
Com toda a certeza se você, entusiasta na área de ciência de dados, já procurou como ler ou fazer análises em um conjunto de dados utilizando a linguagem Python se deparou com o nome Pandas.

Além dos animaizinhos pra lá de fofos, Pandas também é o nome de uma biblioteca poderosa para manipulação e análise de dados utilizando a linguagem Python. Por esse motivo, se você pretende trabalhar na área de análise e ciência de dados com essa linguagem de programação precisa conhecer essa biblioteca e as ferramentas que ele oferece!
O que veremos:
Sobre a biblioteca Pandas Python
Quais as vantagens de utilizar?
Sobre a Biblioteca Pandas Python
Como mencionado anteriormente, Pandas é uma biblioteca para uso em Python, open-source e de uso gratuito (sob uma licença BSD), que fornece ferramentas para análise e manipulação de dados.

Wes McKinney – Criador da Biblioteca Pandas
De acordo com o próprio criador dessa biblioteca, Wes McKinney, o nome Pandas é derivado de panel data (dados em painel), um termo de econometria para conjuntos de dados estruturados. O surgimento da biblioteca, no início de 2008, começou devido a insatisfação de McKinney de obter uma ferramenta de processamento de dados de alto desempenho, com recursos flexíveis de manipulação de planilhas e de banco de dados relacionais.
O pandas permite trabalhar com diferentes tipos de dados, por exemplo:
- Dados tabulares, como uma planilha Excel ou uma tabela SQL;
- Dados ordenados de modo temporal ou não;
- Matrizes;
- Qualquer outro conjunto de dados, que não necessariamente precisem estar rotulados;
A mágica de ler, manipular, agregar e exibir os dados com poucos comandos explica porque a biblioteca tem se tornado tão popular. Aliás, tudo isso é possível devido às estruturas primárias do Pandas, as famosas Series e DataFrames.
Estrutura de Dados
Os dois principais objetos da biblioteca Pandas são as Series e os DataFrames. Uma Serie é uma matriz unidimensional que contém uma sequência de valores que apresentam uma indexação (que podem ser numéricos inteiros ou rótulos), muito parecida com uma única coluna no Excel.
Já o DataFrame é uma estrutura de dados tabular, semelhante a planilha de dados do Excel, em que tanto as linhas quanto as colunas apresentam rótulos.
A partir dos objetos principais a biblioteca Pandas disponibiliza um conjunto de funcionalidades sofisticadas de indexação, que permite reformatar, manipular, agregar ou selecionar subconjuntos específicos dos dados que estamos trabalhando.
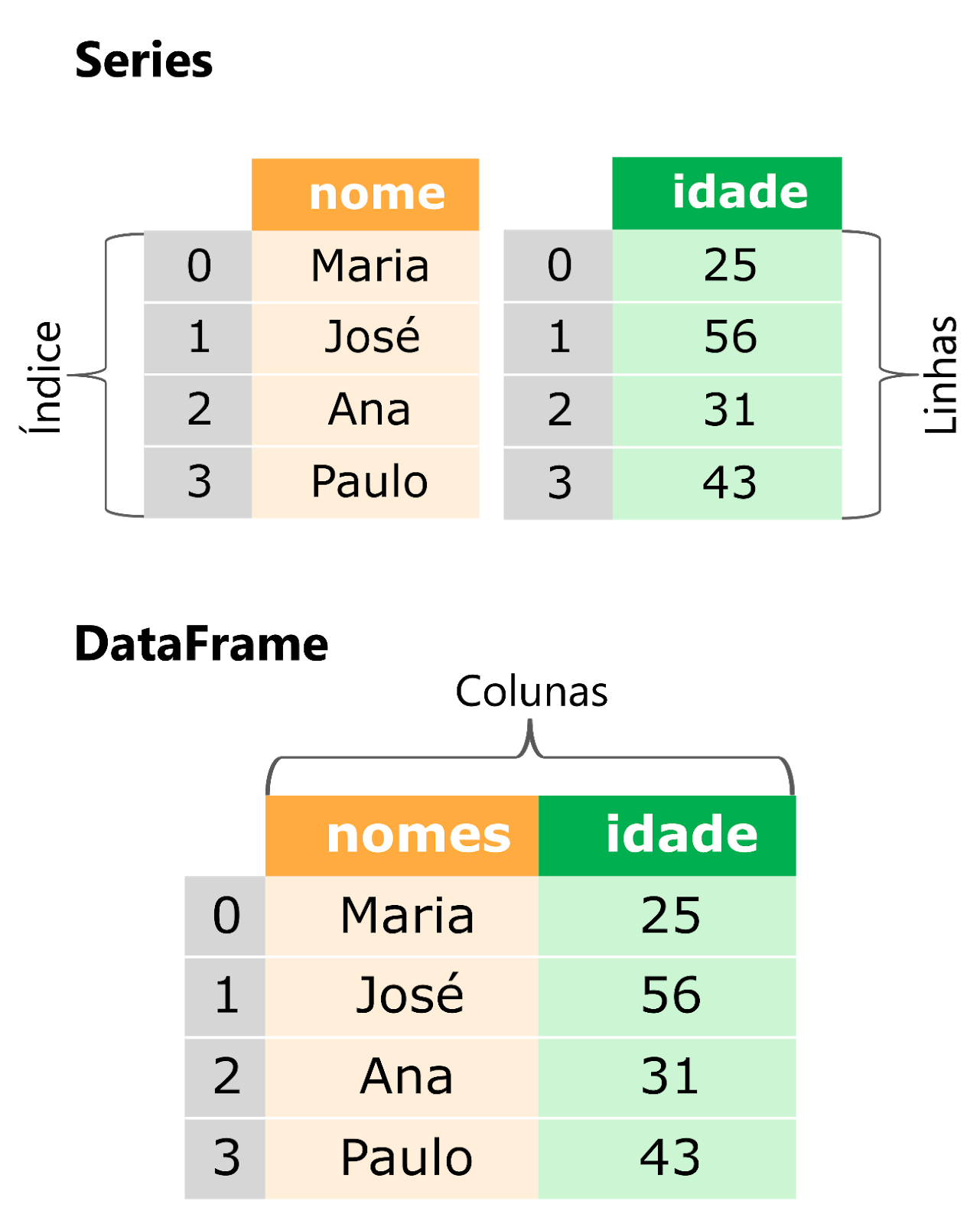
Explicação em linhas visuais sobre Séries e DataFrame
Quais as vantagens de utilizar?
O Pandas reúne muitas vantagens em comparação ao uso de estruturas nativa da linguagem Python, algumas delas são:
- A facilidade de aprender e de utilizar a biblioteca: É muito mais fácil trabalhar com um objeto do Pandas, do que reunir informações por meio de interações de listas e dicionários Python. Para colaborar ainda mais, no seu site a biblioteca ainda disponibiliza uma lista de comandos para que desenvolvedores que utilizam outras linguagens, como R, SQL, SAS, entre outros, possam encontrar os comandos equivalentes, com a mesma funcionalidade no Pandas;

Equivalência dos comandos em R e no Pandas
- Comunidade crescente e muito ativa: Na última pesquisa do Stack Overflow ‘2020 Developer Survey’, o Pandas aparece como quarto colocado na lista de ferramentas e pacotes que os desenvolvedores profissionais utilizam. Geralmente, quanto mais desenvolvedores utilizam uma biblioteca, mais facilidade temos de encontrar soluções para problemas disponíveis na rede. Além da possibilidade de se existir algum bug no pacote, ou em algum método dele, ele ser corrigido mais rapidamente;
- Suporte para alinhamento automático ou explícito dos dados: Os objetos no Pandas podem ser explicitamente alinhados com eixos nomeados, que o usuário pode ou não especificar. Esse alinhamento evita erros comuns de dados desalinhados e possibilita trabalhar com dados que apresentem indexações diferentes (que podem ser provenientes de origens distintas);
- Tratamento flexível e simplificado de dados ausentes: Possibilita de forma simplificada a substituição ou exclusão de dados ausentes que o conjunto de dados que estamos trabalhando pode apresentar;
- Uso de operações: A biblioteca permite a utilização de operações aritméticas para agregar ou transformar os dados que se encontram em suas estruturas principais (Series e DataFrames);
- Combinações e operações relacionais: O Pandas disponibiliza métodos para facilitar a combinação de conjuntos de dados, além de permitir selecionar subconjuntos dos nossos dados originais, com base em determinados filtros;Se você não está por dentro do conceito de filtros no Pandas, aqui vai um vídeo explicando sua utilização:
- Informações estatísticas: Os objetos principais do Pandas apresentam métodos que fornecem informações estatísticas sobre os valores armazenados, como média, mediana, desvio padrão, entre outros;
- Séries temporais: Por ter sido inicialmente projetada para utilização no setor financeiro e de análise de negócios, a biblioteca Pandas fornece um conjunto de recursos para criar e trabalhar com dados indexados por tempo;
- Visualização de dados: Como o Pandas engloba algumas funcionalidades da biblioteca matplotlib, ela permite que os usuários criem visualizações simplificadas dos dados. Embora ela apresente limitação de métodos nesse escopo de visualização, quando comparada a própria matplotlib, ainda é uma funcionalidade muito útil para exploração rápida dos dados;
-

Exemplo de visualização de dados

Exemplo de visualização de dados
- Documentação: A documentação fornecida pela biblioteca Pandas fornece uma rica explicação das estruturas e métodos possíveis de serem aplicadas, descrevendo as funcionalidades e parâmetros existentes. Também, a biblioteca apresenta exemplos de utilização, além de métodos que podem estar relacionados ao método pesquisado.
-

Documentação Pandas

Métodos relacionados – Documentação Pandas

Instalando o Pandas Python
Se finalmente você já está convencido que a biblioteca Pandas pode ser sua poderosa aliada na área de análise de dados, vamos partir para sua instalação!
Em geral a biblioteca Pandas pode ser instalada utilizando o comando pip, que é o gerenciador de pacotes do Python, no terminal de comando do ambiente de programação desejado, por meio da execução:
|
1 |
pip install pandas |
Assim a versão mais atualizada da biblioteca é instalada!
Atenção: Alguns ambientes de programação, como o Anaconda, ao serem instalados já instalam automaticamente alguns pacotes que considerem populares entre os desenvolvedores, como é o caso do Pandas. Se caso você tem dúvidas se o pacote se encontra instalado no seu ambiente de programação, você pode utilizar o comando help:
|
1 |
help('modules') |
Ou se preferir, utilizando o comando freeze do gerenciador de pacote do Python:
|
1 |
pip freeze |
Ambos os comandos devem exibir todos os pacotes que você tenha instalado em seu ambiente de programação, além da versão dos pacotes instalados.
Por onde começar?
Depois da instalação é possível utilizar todos os recursos da biblioteca Pandas na versão escolhida. Que tal agora colocarmos um pouco de mão na massa e explorarmos um pouco das ferramentas dessa biblioteca?

Para começar precisamos informar ao nosso ambiente de programação Python (aqui estamos utilizando o Colab) que queremos desfrutar das ferramentas de uma determinada biblioteca, no nosso caso o Pandas. Como podemos fazer isso? Importando o pacote para nosso ambiente, com o comando import:
|
1 |
import pandas as pd |
Além de importarmos o nosso pacote, adicionamos um “apelido” para ele, denominado pd, para não precisarmos digitar todo o nome pandas quando estivermos utilizando no decorrer do código.
Na sequência podemos ler um conjunto de dados, que neste nosso exemplo será um conjunto fictício de dados de vendas. Essa base de dados tenta emular um conjunto de dados que reúne informações a respeito da venda de determinados produtos, com dados como o índice da compra, dia da venda, qual foi o produto vendido, valor unitário do produto, valor total da compra e a qual setor pertence esse produto vendido.
No Pandas existem vários métodos para leitura de dados com diferentes formatos (como .xlsx, json, .csv). Geralmente, esses métodos iniciam com a palavra ‘read_’ seguido da extensão do arquivo.
|
1 |
df = pd.read_csv('https://raw.githubusercontent.com/brunamulinari/BasicPythonProjects/main/Base_ficticia/baseficticia.csv', sep = ';') |
Note que podemos passar o nome do arquivo e a extensão dele que desejamos ler, salvo em nosso computador, ou um link com o nome do arquivo onde esses dados se encontram. A biblioteca Pandas cuida de toda a parte de se conectar e carregar as informações para o nosso ambiente de programação. O outro parâmetro sep utilizado, trata-se do separador dos dados, que como nesse nosso exemplo trata-se de um arquivo de extensão .csv pode apresentar diferentes tipos de separadores.
Nas funções de entrada existem diversos parâmetros que podem variar dado a extensão do arquivo a ser utilizado, como o caso do parâmetro do separador (sep) para arquivos .csv. Além dessas funções apresentarem parâmetros que indiquem como os dados devem ser carregados dado o desejo do usuário, por exemplo delimitando a quantidade de linhas, quais colunas devem ser utilizadas, o que pode ser considerado como valor faltante, entre outros. Todas as possibilidades de parâmetros encontram-se descritas na documentação do método na biblioteca.
Agora, se pedirmos pro Python que tipo de dado é a variável df que acabamos de criar, utilizando a função anterior read, veremos:
|
1 2 |
type(df) pandas.core.frame.DataFrame |
Temos aqui uma das principais estruturas Pandas, um objeto DataFrame. Assim, podemos começar a explorar um pouquinho das ferramentas da biblioteca.
Vamos começar visualizando as primeiras 6 linhas do nosso conjunto de dados com o método head:
|
1 |
df.head(n=6) |
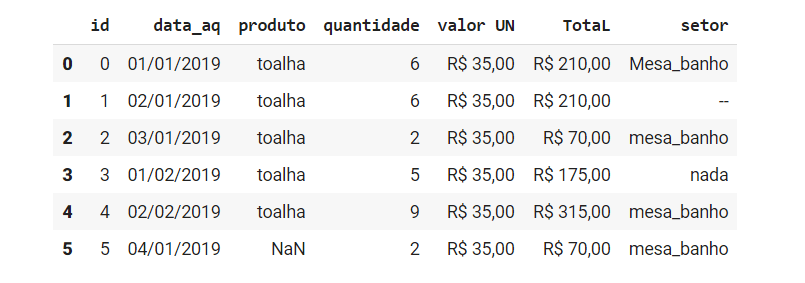
Perceba que nossos dados aparecem estruturados nesse objeto denominado df, de acordo com uma indexação e das colunas nomeadas. Se você observar na sexta linha do nosso DataFrame (índice 5), na coluna produto, temos o famoso NaN (do inglês Not a Number) que indica que no arquivo que utilizamos, naquele espaço, não existia um valor preenchido. Porém, nesse mesmo objeto podemos notar que nas linhas dois e quatro, na coluna de setor, existem valores que foram preenchidos, mas que indicam que naquele espaço podemos considerar uma informação ausente (Essa conclusão acontece quando já conhecemos os padrões que sua equipe ou você mesmo adota para preencher esse banco de dados).
Assim, com esse conhecimento prévio sobre o preenchimento, você pode utilizar de um recurso do Pandas que ao carregar esse conjunto de dados indique quais valores ou mensagens também devem ser considerados ausentes, NaN. Esse recuso é um parâmetro na função de ‘read_’ chamado na_values.
|
1 |
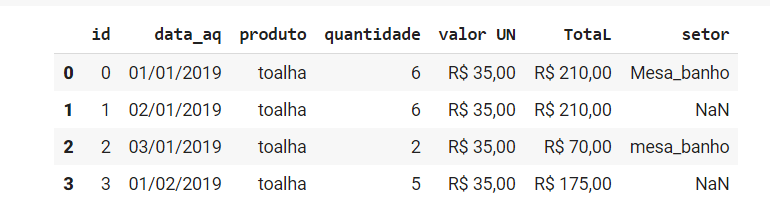
df = pd.read_csv('https://raw.githubusercontent.com/brunamulinari/BasicPythonProjects/main/Base_ficticia/baseficticia.csv', sep = ';', na_values=['--','n/a, 'nada']) |
Agora se visualizarmos novamente os primeiros 4 dados do nosso conjunto, veremos que todos os valores passados para na_values, além dos próprios dados ausentes, foram substituídos por NaN:
|
1 |
df.head(n=4) |
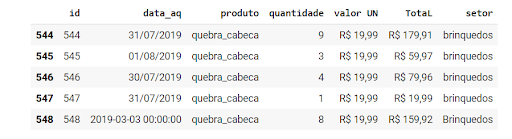
Seguindo com nossa aplicação, também podemos visualizar as 5 últimas linhas do conjunto, com o método tail:
|
1 |
df.tail(n=5) |
Para saber quantas informações esse conjunto de dados apresenta podemos utilizar o comando shape:
|
1 2 |
df.shape (549, 7) |
Perceba que o retorno desse comando é uma tupla de dois valores. O primeiro valor trata-se da quantidade de linhas do conjunto de dados e o segundo a quantidade de colunas.
Já para saber que formato se encontram os dados em cada coluna, além da quantidade de memória para ler esse conjunto de dados, podemos utilizar o comando info:
|
1 |
df.info() |

Em geral, quando a biblioteca não consegue identificar o tipo do dado entre os padrões python conhecidos (int, float, string, datetime, entre outros), ela define o dado com o formato de object.

Na sequência, podemos visualizar quais são nossas colunas existentes e até mesmo alterar esses nomes, basta passar o novo conjunto de nomes desejados com a mesma quantidade de colunas existente no conjunto original:
|
1 2 3 4 |
df.columns Index(['id', 'data_aq', 'produto', 'quantidade', 'valor UN', 'Total', 'setor'], dtype='object') df.columns = ['id', 'data_aq', 'produto', 'quantidade', valor_un', 'valor_total', setor'] |
Somente para conferir se a substituição realizada foi executada com sucesso, vamos visualizar novamente as primeiras duas linhas do nosso DataFrame:
|
1 |
df.head(n=2) |

Como mencionado na seção de vantagens do Pandas, a biblioteca flexibiliza muito a eliminação ou substituição de dados faltantes do nosso conjunto de dados. Para verificar quantos dados faltantes existem em nosso conjunto, podemos utilizar a função isnull, na qual verifica em cada uma das colunas se o elemento é nulo ou não, seguida da função sum, que irá somar todas as respostas verdadeiras obtidas na função anterior, da forma:
|
1 |
df.isnull().sum() |

No Pandas é possível realizar a substituição desses valores nulos de forma bem rápida, basta utilizar o método fillna. Esse método permite substituir os dados faltantes por um valor determinado pelo usuário (informado no parâmetro value) ou utilizar um método de substituição (informado no parâmetro method), que pode, por exemplo, substituir o valor faltante pelo valor anterior válido (método ffill) ou o próximo valor válido (método bfill). Vou deixar aqui como você poderia utilizar essa função de substituição, mas é válido destacar que é necessário ter cautela com o seu uso, pois pode acarretar em erros de análise sobre o conjunto de dados:
|
1 |
df = df.fillna(value=0) |
Ou
|
1 |
df = df.fillna(method='ffill') |
Dado que as colunas que apresentam dados faltantes nesse nosso exemplo de aplicação são dos produtos vendidos e dos setores que esses produtos pertencem, se aplicássemos a função de substituição poderíamos gerar erros nas nossas análises posteriores, por exemplo, na contagem de compras que foram realizadas por setor. Por esse motivo, decidimos que vamos excluir as linhas que apresentam algum elemento faltante. Isso pode ser realizado com o método dropna:
|
1 2 |
df = df.dropna() df.isnull().sum() |
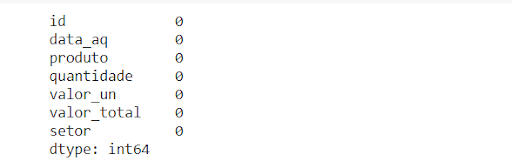
Assim, as linhas que apresentavam alguns dos elementos nulos são eliminadas do nosso conjunto de dados. Simples, não é?

Até aqui utilizamos métodos e atributos referentes a todo nosso conjunto de dados. Porém, podemos visualizar e trabalhar com uma coluna em especifico do nosso conjunto de dados, por exemplo:
|
1 |
df['setor'] |

Quando selecionamos uma coluna em específico no nosso conjunto de dados, passamos a ter o objeto Serie do Pandas:
|
1 2 |
type(df['setor']) pandas.core.series.Series |
No nosso objeto Serie podemos verificar quais os valores únicos existem naquela coluna, com o método unique:
|
1 |
df['setor'].unique() |

Dado que o Python é uma linguagem case sensitive, ela diferencia letras maiúsculas de minúsculas. Por esse motivo, ela diferencia a string ‘informatica’ de ‘Informatica’. No nosso caso, ambas as strings se referem ao mesmo setor da nossa empresa fictícia. Como podemos formatar cada um dos elementos dessa nossa coluna para que eles fiquem todos com letras minúsculas?
O Pandas colabora com a tarefa de formatação de cada elemento de uma Serie disponibilizando o método apply. Com esse método podemos aplicar uma determinada função em cada um dos nossos elementos da coluna:
|
1 2 3 |
def transforma_para_minusculas(x): return(str(x).lower()) df['setor'] = df['setor'].apply(func = transforma_para_minusculas) |
Nesse nosso exemplo, aplicamos a função ‘transforma_para_minusculas’ (que foi definida antes de utilizar o apply) em cada um dos elementos da coluna setor. Essa função utiliza o método do objeto string para transformar todos os caracteres da variável em letras minúsculas. Quer ver como funciona mesmo? Se agora você utilizar novamente o método unique, você verá:
|
1 |
df['setor'].value_counts() |

Gostou? Mas não vamos parar por aqui! Agora que já temos nossos setores formatados, vamos visualizar quantas compras, ou frequência que aparece em nosso conjunto de dados, cada setor tem. Para isso podemos utilizar o método value_counts:
|
1 |
df['setor'].value_counts() |
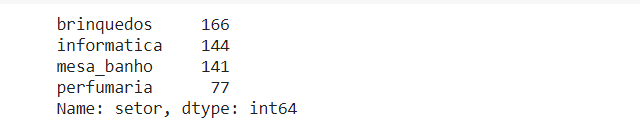
Note que esse método agrupa as informações contidas na Serie dada sua similaridade e apresenta quantas unidades dessa informação aparece no objeto. Ainda a partir desse método podemos gerar uma visualização simples e rápida com o resultado. Como? Com o método plot.
|
1 |
df['setor'].value_counts().plot(kind='bar') |


Também podemos organizar esse resultado para visualizar do menor valor para o maior, empregando o método sort_values, da forma:
|
1 |
df['setor'].value_counts().sort_values(ascending = True) |
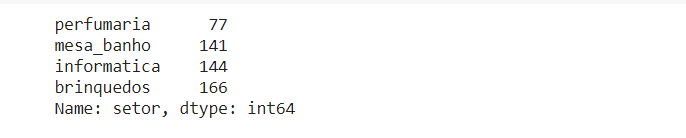
E se você decidir gerar uma visualização disso também é só aplicar o método plot no final. Muito prático, não é?
Agora vamos analisar nossa coluna de valores totais. Com o método info sobre o nosso DataFrame vimos que essa nossa coluna em questão era formada por elementos do tipo object. Mas ela não está apresentando um valor? Por que os elementos não apresentam um formato numérico, tipo int ou float? Isso está ocorrendo no nosso conjunto de dados, pois cada elemento também está apresentando o cifrão da moeda utilizada (nesse caso R$ de reais).
Para transformarmos nossa coluna de valores totais em uma coluna com valores numéricos primeiro precisamos realizar algumas transformações nos elementos.
Vamos começar usufruindo do método map. Esse método apresenta um objetivo muito parecido ao do método apply. Entretanto, o apply pode ser aplicado em objetos do tipo Serie e do tipo DataFrame, enquanto o map somente em objetos Serie.
|
1 |
df['valor_total'] = df['valor_total'].map(lambda x: str(x).replace('R$ ', '')) |
Veja que agora ao invés de passarmos o nome da função que criamos antes de aplicar um método de transformação, estamos utilizando o recurso denominado lambda que permite a criação de funções anônimas em Python. Essa nossa função substitui os caracteres formados pelo cifrão da moeda reais por nada. Podemos verificar o resultado, observando o primeiro elemento da nossa Serie:
|
1 2 |
df['valor_total'][0] '210,00' |
Observe que o cifrão ‘R$’ foi eliminado do nosso elemento. Entretanto, se agora nós tentarmos utilizar o método to_numeric do próprio Pandas nessa Serie, para transformarmos toda a coluna para valores numéricos, teremos um erro na nossa aplicação. Isso ocorre, pois o padrão americano reconhece o ponto como indicação de decimais e não a vírgula. Então precisamos realizar uma nova transformação em nossos dados, substituindo a vírgula por ponto e depois aplicarmos a transformação com o to_numeric.
|
1 |
df['valor_total'] = pd.to_numeric(df['valor_total'].map(lambda x: str(x).replace(',', '.'))) |
Agora nossa coluna apresenta os elementos no formato numérico do tipo float. Quer conferir?
|
1 2 |
df['valor_total'].dtype dtype(float64') |
Como agora a coluna do valor total é no formato numérico, podemos realizar operações aritméticas básicas com ela, por exemplo somar todos os valores dos elementos. Isso pode ser facilmente realizado com o método sum:
|
1 2 |
df['valor_total'].sum() 148230.64 |
E se você somente tem interesse em saber o valor total de um determinado setor? Você pode utilizar de um dos recursos do Pandas para selecionar subconjuntos de informações. Um dos métodos que realiza essa seleção é o método loc. Nesse método, primeiro você passa o índice ou intervalo de índices que pretende selecionar e na sequência passa o nome da coluna ou intervalo de nomes de colunas para seleção, por exemplo:
|
1 |
df.loc[0:3,'id':'valor_un'] |
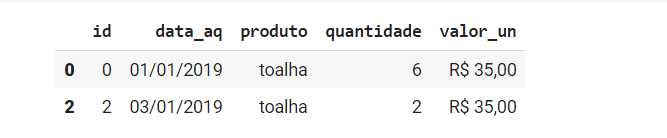
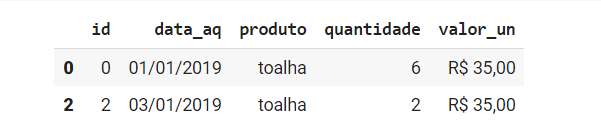
A mesma seleção pode ser realizada utilizando o método iloc, que ao invés de utilizar os nomes das colunas ou nome dos índices utiliza o número da posição deles.
|
1 |
df.iloc[0:2,0:5] |
A partir de um desses dois recursos (vamos utilizar o loc aqui) podemos realizar a seleção de um subconjunto dos dados em que o elemento da coluna setor seja igual a determinado setor, por exemplo, ‘informatica’, além de selecionarmos somente a coluna do valor total, que é a que gostaríamos de somar:
|
1 |
df.loc[df['setor'] == 'informatica', 'valor_total'] |

|
1 2 |
df.loc[df['setor'] == 'informatica', 'valor_total'].sum() 29542.489999999998 |
Por fim, mas não menos importante, uma outra vantagem que discutimos anteriormente foi o quanto o Pandas colabora na exibição de algumas informações estatísticas a respeito do nosso conjunto de dados e permite que possamos realizar facilmente uma análise com o nosso objeto DataFrame. Isso é possível graças a função describe:
|
1 |
df.describe() |
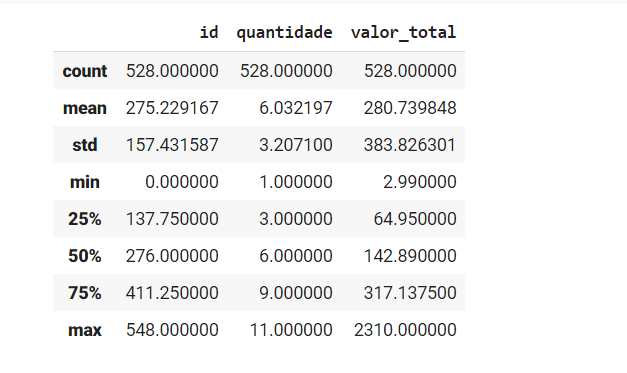
No método describe somente são consideradas as colunas com o formato numérico (int, float). Como é possível observar esse método resulta em medidas estatísticas como a média, a mediana, o desvio e os percentis, que nos permite analisar o comportamento da nossa informação em exibição. Por exemplo, podemos ver que o máximo de itens vendidos no nosso conjunto de dados foi onze unidades e a quantidade mínima é de uma unidade. Mas em média, nas supostas vendas realizadas no nosso conjunto de dados, os consumidores adquiriam seis unidades dos produtos. Muito fácil conseguir obter essas conclusões com o Pandas, não é?
Com o que foi abordado nessa introdução da biblioteca Pandas você já é capaz de usufruir de alguns dos recursos para a exploração, manipulação e visualização de dados com a linguagem Python, utilizando as duas principais estruturas que são as Series e os DataFrames.
Confira também outros exemplos utilizando a Biblioteca Pandas
CURSO COMPLETO PYTHON PANDAS
Espero ter ajudado você a entender um pouco sobre essa biblioteca! Até a próxima!
 Bruna Mulinari
Bruna Mulinari
 Bruna Mulinari
Bruna MulinariFacilitadora na Formação Harve Data Science, Programação Python, Mestra de Engenharia Elétrica e Informática Industrial pela UTFPR, Campus Curitiba, e sócia proprietária da Dataplai. Atua na linha de sistemas embarcados e sistemas inteligentes, com foco em reconhecimento de padrões e processamento de sinais.
O que aprendemos com este artigo?
O que é o Pandas Python?
Pandas é uma biblioteca para uso em Python, open-source e de uso gratuito (sob uma licença BSD), que fornece ferramentas para análise e manipulação de dados.
Quais tipos de dados posso trabalhar com a biblioteca Pandas?
Dados tabulares, como uma planilha Excel ou uma tabela SQL, dados ordenados de modo temporal ou não, matrizes e qualquer outro conjunto de dados, que não necessariamente precisem estar rotulados
Qual a vantagem de se trabalhar com o Pandas para Python?
A mágica de ler, manipular, agregar e exibir os dados com poucos comandos explica porque a biblioteca tem se tornado tão popular. Aliás, tudo isso é possível devido às estruturas primárias do Pandas, as famosas Series e DataFrames.
Como instalar a biblioteca Pandas?
Em geral a biblioteca Pandas pode ser instalada utilizando o comando pip, que é o gerenciador de pacotes do Python, no terminal de comando do ambiente de programação desejado, por meio da execução: pip install pandas
Quais são as ações que posso fazer dentro da biblioteca Pandas?
Alinhamento automático ou explícito dos dados, tratamento flexível e simplificado de dados ausentes, uso de operações, combinações e operações relacionais, informações estatísticas, séries temporais e visualização de dados.
Deixe um comentário