
Na área de ciência de dados com Python certamente você já se deparou com a biblioteca do NumPy. Essa poderosa biblioteca do Python é usada extensivamente por outras bibliotecas super populares, como o Pandas, scikit-learn, matplotlib e em grande parte de bibliotecas voltadas para a área de ciência de dados. Mas você sabe exatamente o que ela faz?
Nesse artigo vamos entender um pouco sobre o pacote NumPy Python, suas estruturas de dados, quais suas vantagens e acompanhar um pequeno tutorial dos primeiros passos para utilizar essa biblioteca.
O que veremos:
Quais as vantagens de utilizar o NumPy Python?
O que é o NumPy?

Criado em 2005 por Travis Oliphant, o projeto NumPy foi baseado nos projetos Numeric e Numarray com o objetivo de reunir a comunidade em torno de um único framework de processamento de arrays. Portanto, o pacote NumPy, denominado dessa forma devido a abreviação de Numerical Python (Python Numérico), é uma biblioteca de código aberto destinada a realizar operações em arrays multidimensionais, amigavelmente denominada como ndarray nesta biblioteca.
Devido sua construção e funcionalidades serem baseadas na estrutura de dados ndarray, a biblioteca oferece operações rápidas para tratamento e limpeza de dados, geração de subconjuntos e filtragens, estatísticas descritivas, manipulação de dados relacionais, manipulações de dados em grupos, entre outros tipos de processamento.
Além dos recursos mais voltados a aplicações de análise de dados, no NumPy Python você também encontrará funções matemáticas para operações rápidas em arrays, sem a necessidade de escrever laços, recursos de álgebra linear, geração de números aleatórios, transformadas de Fourier, ferramentas para trabalhar com dados mapeados em memória, como também uma API para conectar o NumPy Python a bibliotecas escritas em C, C++ e FORTRAN.
Embora a biblioteca NumPy Python não disponibilize funcionalidades científicas, nem de modelagem, compreender esse pacote e a sua principal estrutura, o array, é fundamental para utilizar de modo mais eficaz ferramentas e bibliotecas que são fundamentadas em arrays, como a biblioteca Pandas.
O que são arrays?

Bom, até aqui você já pode perceber que o pacote NumPy Python se baseia em uma estrutura central muito importante. Mas afinal, o que são esses tais arrays?
Um array é uma estrutura multidimensional que nos permite armazenar dados na memória do nosso computador, de modo que cada item localizado nessa estrutura pode ser encontrado por meio de um esquema de indexação. O NumPy Python denomina essa estrutura como ndarray, como forma de abreviação a array N-dimensional.
O ndarray armazena os elementos sempre com o mesmo formato, por isso é conhecido como uma estrutura homogênea de dados, nas dimensões definidas pela aplicação ou pelo desenvolvedor. As dimensões na biblioteca do NumPy são conhecidas como eixos (do inglês axis).
Um ndarray unidimensional, ou seja, que apresenta um eixo (uma dimensão), é muito parecido com a estrutura de listas do próprio Python. Também podemos relacionar esse ndarray a uma coluna ou linha de uma planilha. Já a estrutura ndarray bidimensional, que apresenta dois eixos, é uma matriz na qual podemos relacionar a uma planilha de dados, com colunas e linhas.
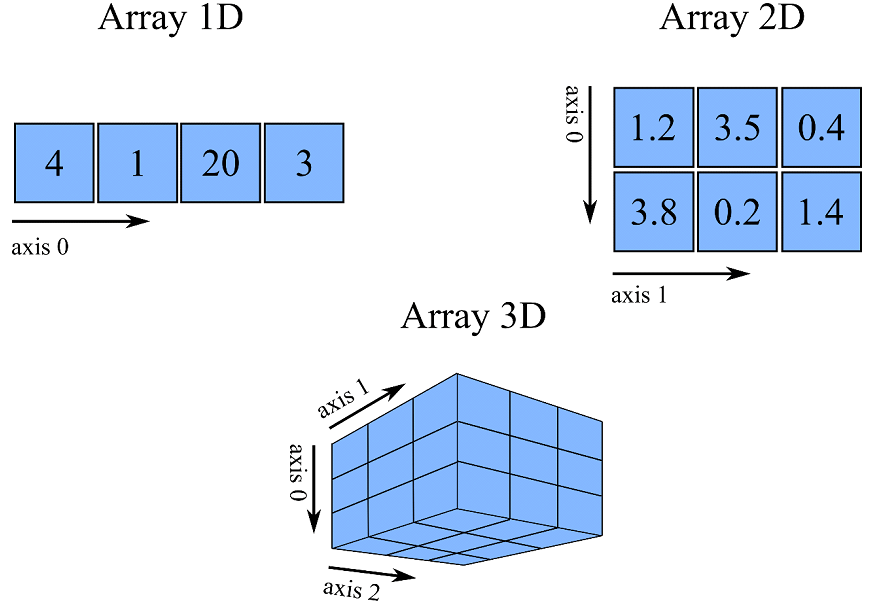
A estrutura tridimensional, ou seja, três eixos, é uma estrutura que armazena informações de três dimensões. Podemos associar que em cada posição dessa estrutura
armazenamos informação da altura, largura e profundidade (x, y e z). Esse tipo de estruturação é muito comum quando trabalhamos com imagens, por exemplo, que apresentam uma altura de pixels, largura e a profundidade relacionada aos canais de cores RGB.
Quais as vantagens de utilizar o NumPy Python?

Na seção anterior, vimos a principal estrutura do NumPy, mas você desenvolvedor python pode estar se perguntando do porquê não utilizar as estruturas nativas da linguagem para armazenar os dados. A resposta a essa pergunta se deve ao NumPy ter sido projetado para ser eficaz em arrays, de modo que:
⦁ Ocupam menos memória: Os dados no NumPy são armazenados em um bloco contínuo de memória, ao contrário de outros objetos do Python. Assim a biblioteca consegue acessar esses dados e modificá-los de modo muito eficiente, conceito chamado de localidade de referência na ciência da computação. Também, visto que os arrays do NumPy não são sequências embutidas eles utilizam uma quantidade menor de memória;
⦁ São mais velozes: As operações que o NumPy disponibiliza são capazes de realizar processamentos complexos em conjuntos de dados, sem a necessidade de laços. Por esse motivo, aplicações que utilizam o NumPy geralmente são de 10 a 100 vezes mais rápidas comparadas a aplicações que utilizam as estruturas/operações nativas do Python;
⦁ Facilidade de execução de cálculos numéricos: A biblioteca do NumPy Python disponibiliza uma variedade de operações para serem realizadas em arrays. Por esse motivo, a biblioteca é muito utilizada em aplicações e bibliotecas que exigem realizar adições, subtrações, multiplicações, transposição, diferenciação, interpolação, entre outras operações com conjuntos de dados, como na área de aprendizagem de máquina, processamento de imagens e rotinas matemáticas.
Toda esta conversa sobre o NumPy Python está muito interessante, mas vamos ver na prática como essa biblioteca funciona e ver a mágica acontecendo?

Instalando o NumPy no Python
Para poder usufruir das operações que o NumPy Python disponibiliza é necessário realizarmos a instalação dessa biblioteca no ambiente em que estamos trabalhando. Então vamos ao código!
A instalação do NumPy pode ser realizada utilizando o gerenciador de bibliotecas do Python, o famoso PIP, por meio do comando:
|
1 |
pip install numpy |
Ou se você utiliza a distribuição do Anaconda, pode utilizar o comando:
|
1 |
conda install numpy |
Com o comando de instalação, a versão mais recente da biblioteca é instalada em seu ambiente de programação. Mas se por algum motivo você precisa instalar uma versão específica do pacote, basta usar o comando:
|
1 |
pip install numpy == 1.11.3 |
Assim, a versão 1.20.3 é instalada no ambiente. Agora se você já apresenta a biblioteca instalada, mas não sabe em qual a versão, pode executar:
|
1 2 |
import numpy print(numpy.__version__) |
Ou se você preferir, utilizar a operação freeze do PIP, que lista todos os pacotes e versões instalados no seu ambiente:
|
1 |
pip freeze |
Para maiores informações sobre a instalação em seu sistema operacional é válido consultar a documentação da biblioteca.
Biblioteca instalada, podemos começar a usufruir dos recursos que ela disponibiliza!
Por onde começar?
Como qualquer outra biblioteca em Python, para poder usufruir do NumPy é necessário realizarmos a importação do pacote para nosso ambiente de programação. A importação pode ser realizada pelo comando:
|
1 |
import numpy as np |
Por meio desse comando nosso ambiente entende que iremos utilizar as operações que estão salvas na biblioteca NumPy Python. Além de sinalizarmos que utilizaremos as funções do pacote, estamos atribuindo um “apelido” a ele. Esse apelido é uma convenção e agiliza no desenvolvimento, dado que não necessitamos escrever todo o nome da biblioteca, somente o np.
É possível utilizar outro comando de importação em seu código a fim de poupar a chamada do pacote todas as vezes necessárias:
|
1 |
from numpy import * |
Porém, esse comando deve ser utilizado com cautela, visto que uma série de funções do NumPy Python apresentam nomes semelhantes a funções embutidas em Python, como as funções min e max. Por esse motivo, os próximos comandos são considerando o primeiro formato de importação.
Com a importação realizada, vamos começar com a criação de arrays no NumPy!
Uma das maneiras mais fáceis de criar um array é utilizando a função que leva o mesmo nome. Nessa função, qualquer sequência de dados (incluindo outros arrays) são convertidos para uma array NumPy, ou ndarray.
|
1 2 |
minha_mista = [6, 7.5, 8, 1, 2] meu_array = np.array(minha_mista) |
A partir de uma lista convertemos nosso dado para um ndarray. Vamos visualizar essa nossa estrutura?
|
1 |
print(meu_array) |
Output:
|
1 |
[6. 7.5 8. 1. 2. ] |
Você notará que a estrutura gerada é muito similar a estrutura da lista que apresentávamos, com somente um eixo. Entretanto, já é possível notar que todos os elementos do ndarray receberam um ponto, pois todos foram convertidos para o mesmo tipo de dado (nesse caso, float). O NumPy Python, caso o tipo não seja especificado, sempre tentará inferir um bom tipo para a estrutura que ele criar. Agora vamos criar um ndarray com mais dimensões e com o tipo dos elementos definidos por nós:
|
1 2 3 |
dado = [[1.0,2,3],[4,5.0,6]] meu_array_2 = np.array(dado, dtype=int) print(meu_array) |
Output:
|
1 2 |
[[1 2 3] [4 5 6]] |
Nesse nosso exemplo temos um ndarray com dois eixos, em que todos os elementos foram convertidos para inteiros (int), conforme definimos. Essa disponibilidade é útil quando necessitamos ter mais controle sobre como nossos dados são armazenados na memória, principalmente se tratando de grandes conjuntos. Você pode conferir todos os tipos de dados disponíveis na documentação da biblioteca!
Além da função np.array, existem uma variedade de funções que nos permite criar novos arrays. Como a função zeros:
|
1 2 3 |
arr_zeros = np.zeros((3,4), dtype=int) print(arr_zeros) |
Output:
|
1 2 3 |
[[0 0 0 0] [0 0 0 0] [0 0 0 0]] |
Essa função cria um ndarray, com o tamanho especificado, em que todos os elementos serão iguais a zero. No nosso exemplo, especificamos dois eixos, o primeiro eixo com um tamanho 3 e o segundo com tamanho 4. Podemos associar o nosso primeiro eixo com a quantidade de linhas (ou colunas no caso do ndarray unidimensional) e o segundo eixo com a quantidade de colunas do nosso conjunto de dados.
Outra função muito parecida com a zeros é a função ones. Nela os nossos elementos são todos iguais ao valor um:
|
1 2 3 |
arr_ones = np.ones((2,3), dtype=int) print(arr_ones) |
Output:
|
1 2 |
[[1 1 1 [1 1 1]] |
A biblioteca do NumPy oferece outras funções com uma finalidade muito parecida. A Tabela a seguir reúne uma pequena lista com as funções que podemos utilizar para criação de arrays com o NumPy Python.

Como podemos visualizar nos exemplos anteriores que realizamos, o ndarray contém dados homogêneos, então todos os elementos são do mesmo tipo. E se ao longo da minha aplicação eu gostaria de saber a que tipo eles pertencem?
Podemos utilizar os atributos que o ndarray apresenta! Entre eles temos o atributo dtype, que retorna o tipo dos nossos elementos:
|
1 2 3 |
meu_array = np.arange(15) print(meu_array.dtype) |
Output:
|
1 |
Int64 |
Neste exemplo criamos um ndarray unidimensional, com um intervalo de 15 valores de 0 até 14 e o seu tipo foi definido como int64.
Outro atributo que todo ndarray apresenta é o shape, que retorna uma tupla com o tamanho de cada dimensão:
|
1 2 3 |
arr_ones = np.ones((2,3), dtype=int) print(arr_ones.shape) |
Output:
|
1 |
(2,3) |
Se você já chegou a trabalhar com a biblioteca Pandas, deve ter se deparado com atributos muito parecidos com o shape e o dtype, para as estruturas Series e Dataframes.
Outros atributos que você pode encontrar em um ndarray é o ndim e o size, nas quais retornam à quantidade de dimensões do array e a quantidade de elementos que ele armazena, respectivamente.
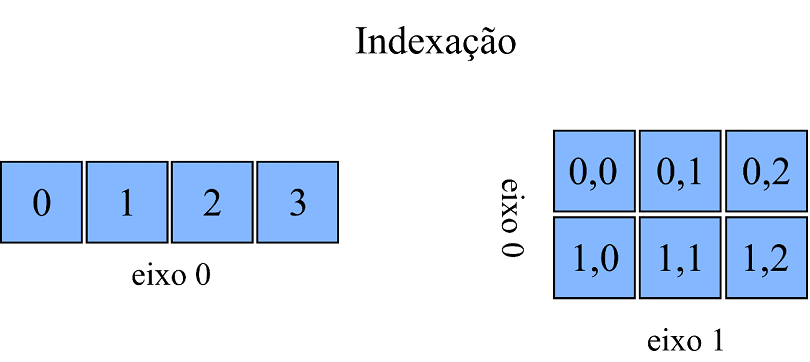
Agora que aprendemos a criar os ndarrays vamos ver como podemos selecionar e alterar a informação de elementos em posições específicas. A indexação de arrays pode ser realizada de diferentes formatos, selecionando um subconjunto de dados ou elementos individuais. Em ndarrays unidimensionais, a indexação é semelhante às listas:
|
1 2 3 |
meu_array = np.arange(15) print(meu_array[2]) |
Output:
|
1 |
2 |
Assim acessamos o nosso terceiro elemento. Lembrando que as indexações tanto em Python nativo, quanto no numpy, começam em zero. Caso desejamos fazer uma alteração do valor desse terceiro elemento:
|
1 2 3 4 5 |
meu_array = np.arange(15) meu_array[2] = 25 print(meu_array) |
Output:
|
1 |
[0 1 25 3 4 5 6 7 8 9 10 11 12 13 14]> |
O mesmo é válido para selecionarmos um subconjunto de dados:
|
1 2 3 |
meu_array = np.arange(15) print(meu_array[5:8]) |
Output:
|
1 |
[5 6 7] |
Nesse exemplo selecionamos do sexto ao sétimo elemento do nosso conjunto. Uma diferenciação com as listas embutidas de Python é que os subconjuntos dos arrays são visualizações do array original. Por esse motivo, se realizarmos qualquer modificação em uma visualização, alteramos nosso array original. Se caso você deseja realmente copiar o array pode utilizar o método copy:
|
1 |
meu_array[5:8].copy() |
Fonte: Adaptado de Python for Data Analysis (MCKINNEY, 2018).
Já a indexação de arrays multidimensionais exigem um pouco mais de atenção, pois para acessarmos os elementos individuais precisamos passar uma lista de índices separados por vírgula:
|
1 2 3 4 5 |
dado = [[9,22,13],[8,25,16]] meu_array = np.array(dado, dtype=int) print(meu_array[1,0]) |
Output:
|
1 |
8 |
Nesse exemplo criamos um ndarray com os dados informados e acessamos o elemento que se encontra na segunda linha, primeira coluna. Se nosso array apresentasse mais uma dimensão, para acessar um de seus elementos, precisaríamos acrescentar o valor da posição no final da lista.

Fonte: Adaptado de Python for Data Analysis (MCKINNEY, 2018).
Outra forma de selecionarmos elementos em nosso array é por meio da indexação booleana. Assim podemos passar uma sequência de elementos verdadeiro/falso ou uma expressão booleana para selecionarmos os elementos. Vejamos no exemplo:
|
1 2 3 4 5 6 7 |
dado = np.random.randn(5) print(dado) arr_bool = [True, False, False, True, False] print(dado[arr_bool]) |
Criamos um ndarray com 5 posições de modo aleatório. A nossa primeira visualização (primeiro print) deve exibir esse nosso array de dados completo. Enquanto que a nossa segunda visualização, exibe somente a primeira e a quarta posição desse array de informações, dado que nosso vetor booleano apresenta como verdadeiro somente esses elementos.
Visto que um ndarray permite a indexação booleana, podemos utilizar esta propriedade para realizar filtros nos nossos conjuntos de dados, por exemplo:
|
1 2 3 4 5 6 7 |
nomes = np.array([‘João’, ‘Pedro’, ‘Ana’, ‘Paulo’, ‘Maria’, ‘Isabela’, ‘João’]) filtro = nomes == ‘João’ print(filtro) print(nomes[filtro]) |
Output:
|
1 2 |
[True False False False False False True] [‘João’ ‘João’] |
No exemplo criamos um ndarray no qual armazenamos um conjunto de nomes. Desse conjunto só queremos selecionar os elementos que apresentam o nome igual a João. Perceba que ao visualizarmos nosso filtro, somente o primeiro e o último elemento do array aparecem como verdadeiro, dado que satisfazem a condição que estabelecemos. Na sequência, imprimimos nosso vetor de nomes somente com a indexação booleana criada por nosso filtro.
O filtro que criamos no exemplo anterior utiliza uma expressão de igualdade, mas outras expressões podem ser utilizadas como maior (>), menor (<), diferente (!=), entre outras que utilizam os operadores relacionais. É válido destacar que as palavras and e or não funcionam em arrays booleanos, então caso você necessite faça a substituição por & (and) e I (or).
Ainda sobre o exemplo anterior, utilizamos uma seleção por meio de um array booleano, mas e se o nosso desejo fosse saber em que posições (índices) se encontram os elementos que satisfazem nossa expressão relacional?
Para saber as posições que a condição é satisfeita podemos utilizar a função where da biblioteca. Vejamos:
|
1 2 3 |
nomes = np.array([‘João’, ‘Pedro’, ‘Ana’, ‘Paulo’, ‘Maria’, ‘Isabela’, ‘João’]) print(np.where(nomes==’João’)) |
Output:
|
1 |
(array([0,6]),) |
Perceba que agora ao invés de obtermos como retorno os elementos que satisfazem nossa condição, recebemos um novo array com seus elementos iguais as posições do nosso array original nas quais a condição foi satisfeita. Portanto, em nosso exemplo, no índice um e seis do vetor original.
Até agora vimos como criar e selecionar/encontrar elementos em nossos arrays no NumPy Python. Porém essa biblioteca é muito conhecida devido a sua capacidade de realizar operações sobre essas estruturas. Vamos começar olhando para as operações denominadas como universais na biblioteca.
Funções universais realizam determinadas operações em todos os elementos nos dados de ndarrays. Nelas podemos passar um ou mais arrays e gerar um ou mais resultados.
Muitas funções universais geram transformações simples em todos os elementos, por exemplo, a geração de uma novo array com as raízes quadradas e com a exponenciação, com as funções sqrt e exp.
|
1 2 3 4 5 |
dados = np.arange(5) print(dados) print(np.sqrt(dados)) |
Output:
|
1 2 |
[0 1 2 3 4] [1. 2.71828183 7.3890561 20.08553692 54.59815003] |
Nesse nosso exemplo, primeiro visualizamos nosso array original e na sequência a raiz quadrada de cada um dos elementos.
|
1 2 3 4 5 |
dados = np.arange(5) print(dados) print(np.sqrt(dados)) |
Output:
|
1 2 |
[0 1 2 3 4] [1. 2.71828183 7.3890561 20.08553692 54.59815003] |
Já nesse nosso exemplo, também primeiro visualizamos o array original e na sequência a exponenciação eX de cada elemento. As funções sqrt e exp são denominadas como funções universais unárias, pois permitem um array e calculam uma operação sobre cada um dos seus elementos. Outras funções que permitem dois arrays como parâmetros são denominadas funções universais binárias e devolvem um único array como resultados, como é o caso das funções add e power:
|
1 2 3 4 5 6 7 8 9 10 11 |
a = np.arange(5) b = np.array([2, 5, 9, 2, 4]) c = np.add(a,b) print(a) print(b) print(c) |
Output:
|
1 2 3 |
[0 1 2 3 4] [2 5 9 2 4] [2 6 11 5 8] |
No exemplo, criamos três arrays (a, b e c), em que nosso terceiro array é resultante da função add na qual soma os elementos correspondentes nos arrays a e b. Já a função power eleva os elementos do primeiro array nas potências indicadas pelo segundo, vejamos:
|
1 2 3 4 5 6 7 8 9 10 11 |
a = np.arange(3) b = np.array([2, 3, 4]) c = np.power(a,b) print(a) print(b) print(c) |
Output:
|
1 2 3 |
[0 1 2] [2 3 4] [0 1 16] |
As funções universais unárias e binárias são alguns entre várias que a biblioteca NumPy Python oferece. As tabelas a seguir apresentam mais algumas operações disponíveis que você pode testar depois!

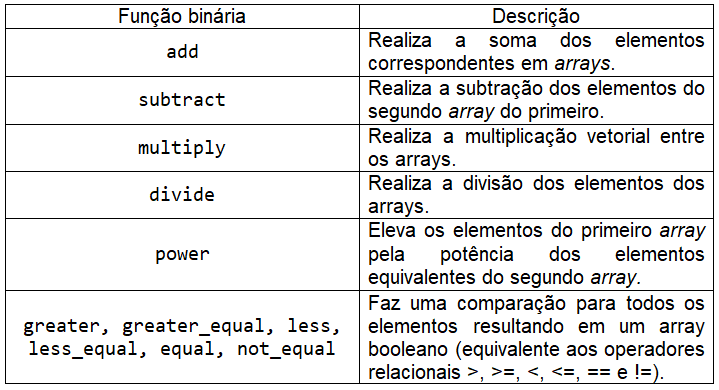
As funções binárias discutidas nesse artigo realizam operações entre arrays com tamanhos semelhantes ou entre um array e um valor escalar. Existem operações com arrays de tamanhos distintos, elas são chamadas de broadcasting e pode ser um tema de uma outra conversa nossa!
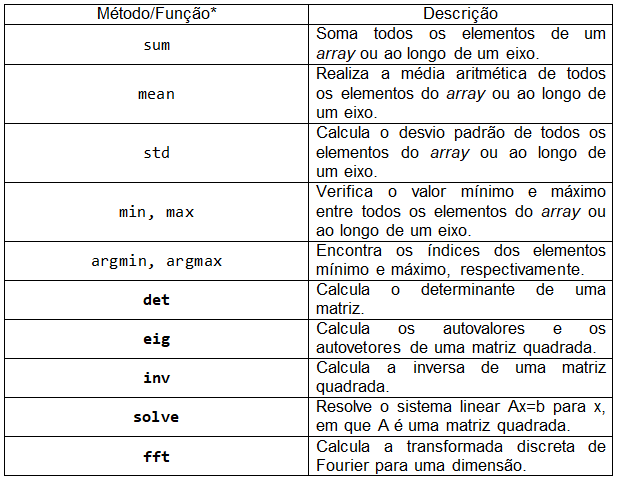
Além das funções universais, o NumPy Python disponibiliza uma gama de funções estatísticas, de álgebra linear e de transformadas, o que nos auxilia muito no momento de realizar alguns cálculos e análises. As funções sum, mean e transpose, são exemplos disso:
|
1 2 3 |
arr = np.array([[1,2,3], [7,8,9]]) print(arr.sum()) |
Output:
|
1 |
30 |
A função sum é utilizada para agregações dos elementos do array. Portanto, nosso resultado do exemplo é o somatório de todos os elementos do array. Essa função aceita um argumento opcional, denominado axis, no qual calcula a estatística no eixo especificado. Vejamos:
|
1 2 3 |
arr = np.array([[1,2,3], [7,8,9]]) print(arr.sum(axis = 0)) |
Output:
|
1 |
[8 10 12] |
Assim temos o total de cada coluna, pois os elementos nas linhas foram somados.
O argumento axis também pode aparecer na função mean, que é destinada a obter a média do array:
|
1 2 3 |
arr = np.array([[1,2,3], [7,8,9]]) print(arr.mean(axis = 1)) |
Output:
|
1 |
[2. 8.] |
Assim calculamos a média final de cada linha utilizando os valores dos elementos em cada coluna da respectiva linha.
Já o método T é utilizado para calcular a transposta do nosso array:
|
1 2 3 4 5 |
arr = np.array([[1,2,3], [7,8,9]]) print(arr) print(arr.T) |
Output:
|
1 2 3 4 5 6 |
[[1 2 3] [7 8 9]] [[1 7] [2 8] [3 9] |
A próxima tabela apresenta outros métodos e funções estatísticas e de álgebra linear que você pode utilizar:
*Funções em negrito.
Bom pessoal, este texto poderia se prolongar por várias e várias páginas e talvez ainda não conseguiria mostrar pra vocês tudo que a biblioteca do NumPy Python pode realizar! Porém, espero que com esta introdução você tenha entendido o porquê desse pacote ser muito utilizado por outros pacotes, além de ser uma ferramenta e tanto para processamento numérico com Python. Até a próxima!
 Bruna Mulinari
Bruna Mulinari
Facilitadora na Formação Harve Data Science, Programação Python, Mestra de Engenharia Elétrica e Informática Industrial pela UTFPR, Campus Curitiba, e sócia proprietária da Dataplai. Atua na linha de sistemas embarcados e sistemas inteligentes, com foco em reconhecimento de padrões e processamento de sinais.
O que aprendemos nesse artigo:
O que significa NumPy?
A abreviação NumPy significa Numerical Python (Python Númerico), tudo isso devido ao fato de ser baseado nos projetos Numeric e Numarray que foi feito com objetivo de reunir a comunidade em torno de um framework de processamento Arrays.
Porque utilizar o NumPy ao invés das estruturas nativas do python?
Porque o Numpy ocupa menos memória, é mais rápido (pois é mais próximo a linguagem de baixo nível) e possui mais facilidade de execução de calculos numéricos.
Como começar com o NumPy?
Como qualquer outra biblioteca em Python, para poder usufruir do NumPy Python é necessário realizarmos a importação do pacote para nosso ambiente de programação.
Onde o NumPy é bastante utilizado?
O NumPy é bastante utilizado no campo da ciência de dados, pois permite com que armazene e processe os dados de forma mais eficiente.
O que são Arrays?
Um array é uma estrutura multidimensional que nos permite armazenar dados na memória do nosso computador, de modo que cada item localizado nessa estrutura pode ser encontrado por meio de um esquema de indexação. O NumPy denomina essa estrutura como ndarray, como forma de abreviação a array N-dimensional.
Deixe um comentário