
Autor: João Guilherme Taverna
Muito tem se falado sobre a linguagem de programação “do momento” nos últimos tempos. Fácil, intuitiva, poderosa: são apenas alguns dos adjetivos encontrados para descrever a linguagem Python e suas inúmeras funcionalidades, frente a um visível crescimento em sua utilização.
Ao longo dos meses de agosto e setembro de 2021, participei do curso de Programação Python ministrado na Harve e pude ver com meus próprios olhos do que realmente se tratava, tendo sido possível entender o porquê de sua popularidade. Durante o curso aprendemos desde o mais básico – como a instalação do Python em sua máquina ou conceitos básicos de lógica de programação – até assuntos um pouco mais complexos, como o desenvolvimento web, por exemplo.
Acredito que cada um dos alunos tenha ingressado no curso com um objetivo diferente, visto que as aplicações para o Python são diversas, porém no meu caso já existia um interesse específico pela área de análise de dados. Desta forma, ao ter contato com o módulo que abordava a utilização do Python para tal, tive a certeza do poder que essa ferramenta possui e o quanto é capaz de agregar na rotina de um profissional que lida com uma imensa gama de dados e informações diariamente.
Sendo assim, como projeto final do curso, decidi optar por realizar uma breve análise de dados com a utilização da biblioteca Pandas, numa forma de demonstrar alguns dos conhecimentos adquiridos em sala de aula.
Tendo em vista um melhor entendimento, separei o projeto final nas seguintes etapas:
-
OBTENÇÃO DOS DADOS
Ao me deparar com a proposta que imaginei para o projeto final, inicialmente encontrei dificuldade para decidir o que exatamente eu iria analisar, visto que no momento não atuo em uma área que envolva a manipulação de dados como planilhas, por exemplo. Desta forma, após algumas pesquisas encontrei o site mockaroo.com, que se trata de uma API que gera dados aleatórios em diversos formatos de arquivo, entre eles o formato CSV.
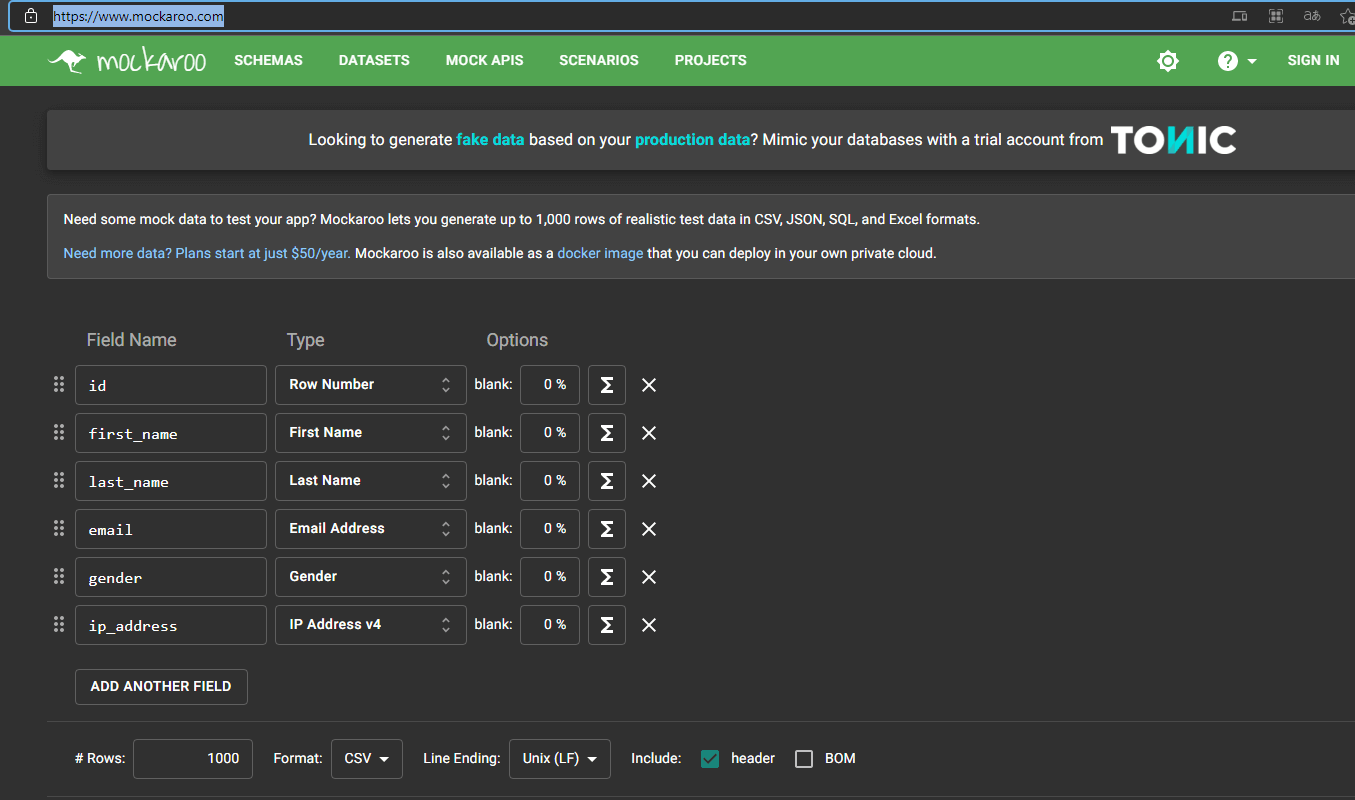
Dentro da plataforma é possível moldar a base de dados que você pretende gerar, inserindo o nome das colunas no campo “Field Name” e o tipo de dado existente em cada coluna por meio do campo “Type”.
Vale lembrar que a escolha dos nomes das colunas é arbitrária, porém a escolha dos dados contidos em cada coluna é realizada com base numa série de dados que a API proporciona, como por exemplo: datas, nomes, números de cartão de crédito, URLs, endereços de e-mail, entre outros.
Decidi pensar em um problema que envolvesse uma planilha com dados referentes às últimas mil compras realizadas em um determinado e-commerce. As colunas foram então escolhidas como sendo: “First Name”, “Last Name”, “Email”, “Gender”, “Purchase” e “Credit Card”. Selecionei os respectivos tipos de dados para cada coluna, e em seguida realizei o download do arquivo CSV.
Como optei por não utilizar a versão paga da API, fiquei limitado à versão grátis que disponibiliza um banco de dados com “apenas” mil linhas, mas que já é suficiente para a demonstração do projeto.
-
TRATAMENTO DOS DADOS
Tendo posse dos dados que vão ser analisados, é hora de visualizá-los em sua forma bruta e, caso necessário, tratá-los para que possam ser manipulados por meio da programação. Ou seja, nessa etapa basicamente é onde os dados são padronizados para que possam ser adequados ao Python.
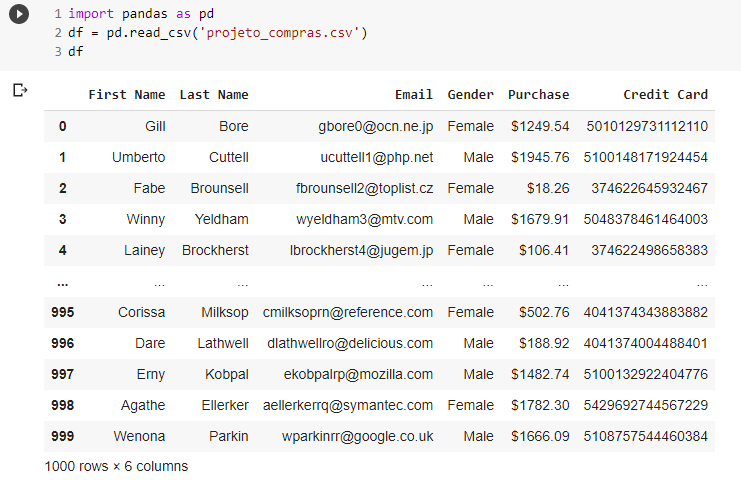
O primeiro passo é importar a biblioteca Pandas, dando um “apelido” para ela (no caso, “pd”). Em seguida, inserimos um data frame que irá ler o arquivo CSV e realizar a visualização da planilha. Para isso, utiliza-se dos seguintes comandos:
- import pandas as pd
- df = pd.read_csv(‘projeto_compras.csv’)
- df
A primeira linha refere-se à importação da biblioteca. A segunda, atribui à variável “df” a leitura do arquivo csv que será analisado, e a terceira, por fim, visualiza o data frame.
Ao visualizar o data frame pode-se ter uma ideia das informações contidas nele. Porém, visualizar mil linhas de forma manual provavelmente seria uma tarefa chata e cansativa. Assim, um comando interessante para começar a análise pode ser o seguinte:
- df.info()
Este comando é um método Pandas, que mostra informações do objeto data frame, incluindo o tamanho do data frame, tipo de dado de cada coluna, valores nulos, e memória usada.
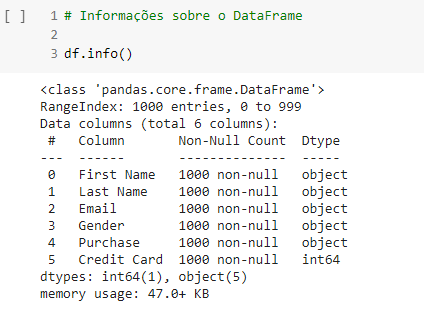
Trata-se de uma etapa importante da análise preliminar, pois é aqui onde podemos ter uma ideia do tratamento dos dados que será necessário. Por exemplo: existem colunas com valores vazios? Se sim, estes valores vazios estão padronizados? E mais, os valores vazios são relevantes para a análise?
Bom, neste caso, ao criar a base de dados no Mockaroo, optei por não agregar valores vazios aos dados, por isso pode-se verificar que todos os valores são caracterizados como “non-null”.
A partir disto, já pensando numa possível análise, resolvi verificar se a distinção de clientes por gênero poderia ser plausível para explicar algum evento extraordinário que fizesse mais homens ou mais mulheres terem realizado compras.

Nesse caso o comando utilizado começa com df[‘Gender’], que serve para selecionar apenas a coluna “Gender” do data frame. Em seguida, usa-se do método value_counts() para contar os valores únicos contidos na série (coluna).
Temos que existe uma leve diferença entre a quantidade de homens e mulheres que realizaram compras, e assim decidi que a distinção por gênero no momento não traz significância para a análise. Seguimos.
Logo de início, é possível perceber que o data frame possui dados não padronizados, que poderão complicar ou inviabilizar a análise. Por exemplo, os nomes das colunas contém espaços, e a coluna “Purchase” possui o caractere especial de cifrão em seus valores, o que significa que teremos que alterar estes dados. Para padronizar as séries pandas (colunas), é preciso renomeá-las. Para isso, existe um método do pandas específico:
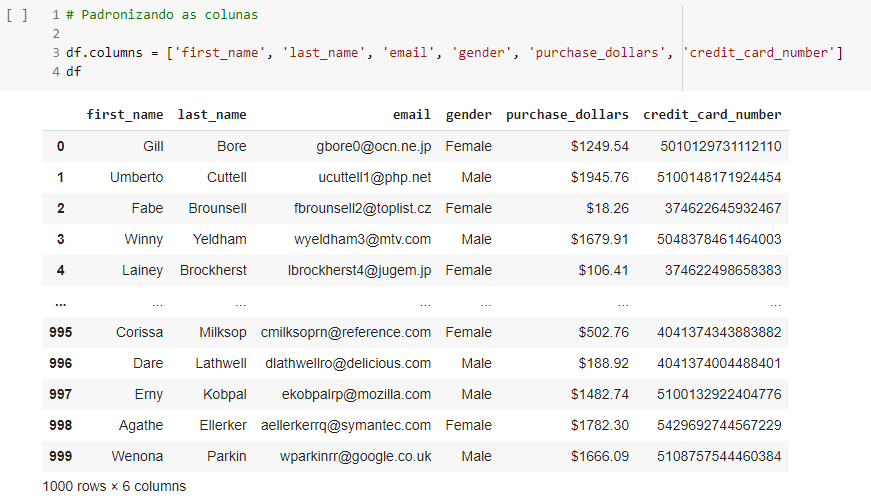
Ao utilizar o comando df.columns, é necessário descrever uma lista de strings que serão os novos nomes das colunas. É válido lembrar que esta lista deve conter o mesmo número de strings que o data frame original continha antes. Pode-se perceber que os nomes das colunas foram padronizados.
Agora, é hora de remover o caractere especial de toda a coluna “purchase_dollars” do data frame. Inicialmente, procurei criar uma função genérica que pudesse ser aplicada à uma série Pandas.
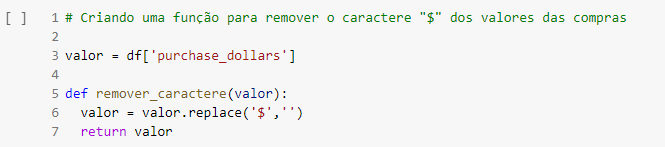
A função em questão depende do parâmetro “valor”. Este parâmetro foi definido para ter seu valor inicial como sendo a própria coluna com o valor das compras. Feito isso, dentro da função, foi atribuído ao “valor” o método replace, que se torna responsável por checar o caractere “$” em cada linha da respectiva coluna, trocando este caractere por um espaço em branco, e por fim retornando o “valor” já alterado.
Agora resta aplicar essa função à coluna de fato. Para isso, foi feito o seguinte:
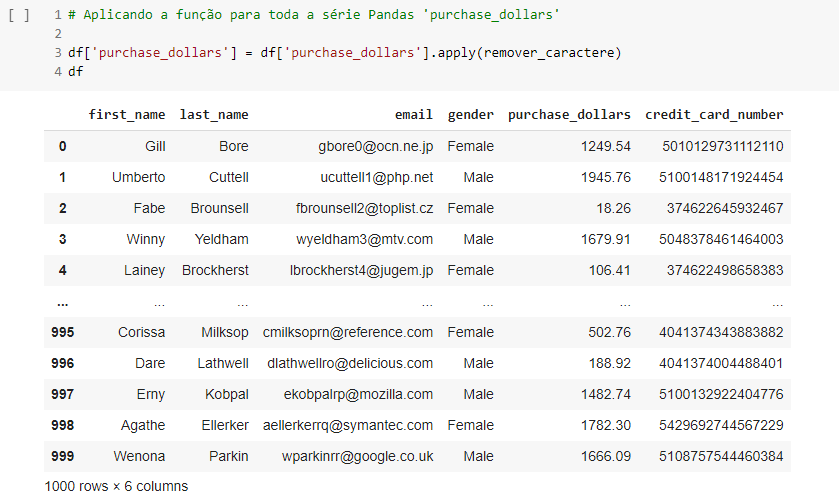
Onde nessa etapa, apenas foi aplicada a função “remover_caractere” para toda a coluna de fato.
Mas será que isso é suficiente? A resposta é: não. Em seguida, é necessário transformar os valores desta coluna para um tipo de dado numérico, visto que no momento trata-se de um dado do tipo object.
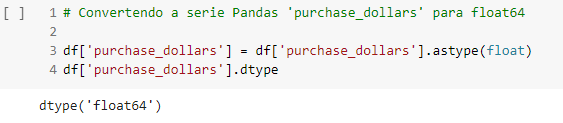
Um processo bem simples, mas que é totalmente necessário para que seja possível realizar análises numéricas nesta coluna. Utiliza-se do método astype(float) para formatar os dados da coluna para o tipo float. A última linha refere-se apenas à verificação do tipo de dados que a coluna contém, confirmando que a alteração foi de fato concluída.
-
FILTRAGEM DOS DADOS E ANÁLISES
Dando sequência, logo após realizar o tratamento dos dados é necessário moldá-los de acordo com a proposta de análise a ser realizada. Decidi que a análise giraria em torno da seguinte proposta:
- Encontrar o faturamento total;
- Encontrar a média de valor gasto pelos clientes;
- Selecionar as compras acima de mil dólares, para que sejam enviados cupons de desconto para as próximas compras dos respectivos clientes.
Para isso, vamos manipular mais uma vez os dados:

Onde foi realizado apenas um somatório dos valores contidos na coluna “purchase_dollars”, por meio do método sum().
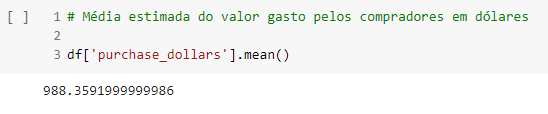
Nesse caso, foi realizado o cálculo da média dos valores da coluna, por meio do método mean().
Agora, a filtragem dos valores da coluna para compras acima de mil dólares:
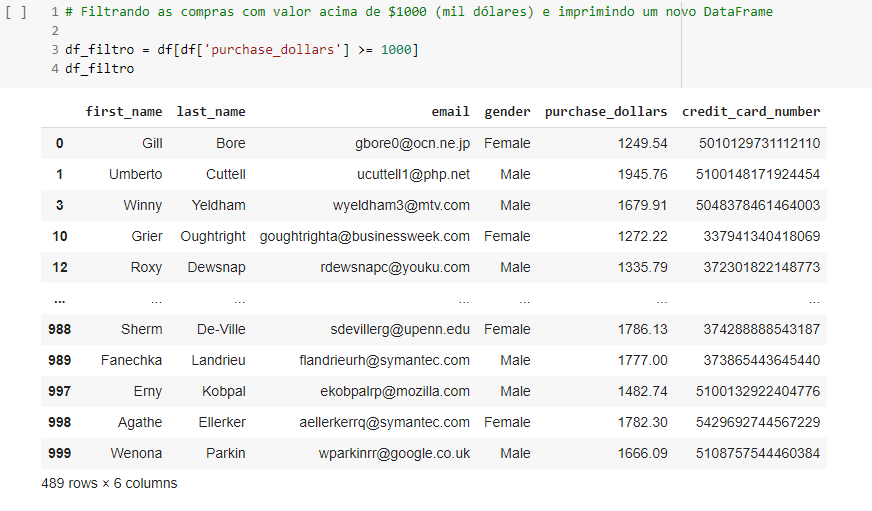
Nesta etapa, apenas atribui a um novo data frame o filtro do data frame original, selecionando apenas valores maiores ou iguais a mil.
Note que a tabela agora não contém mais mil linhas, mas apenas 489. Isso confirma que o filtro foi de fato aplicado. Outro ponto a ser notado, é que o index foi tirado de ordem, visto que houve linhas apagadas nesse processo. Se desejar, é possível resetar o valor do index para que ele fique ordenado novamente.
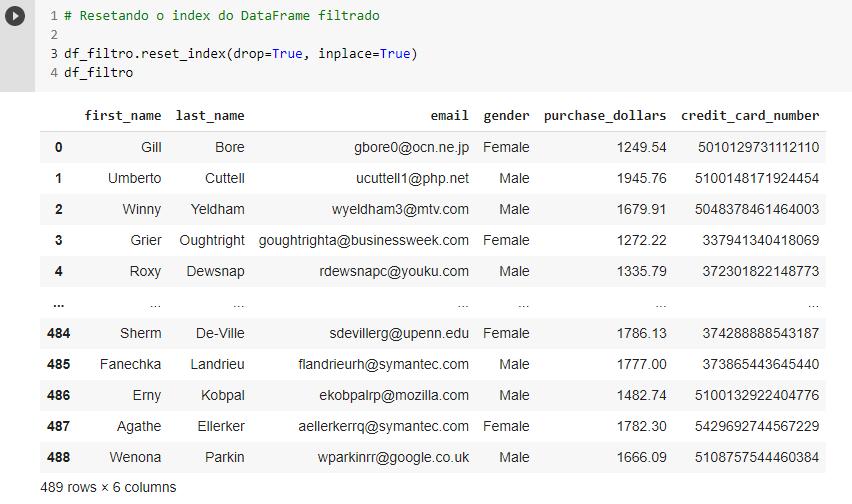
Aqui, aplicamos o método reset_index() ao data frame filtrado, colocando os argumentos drop = True e inplace = True para que a coluna com os index antigos seja descartada. Sendo assim, nesta etapa o código Python para este projeto está finalizado.
-
RESUMO DA ANÁLISE
Tendo em vista o que foi proposto para esta análise, foi possível concluir que:
- O faturamento total, referente às mil compras, foi de $988,359.2
- O valor médio das compras foi de: $988.35
- 489 clientes realizaram compras acima de $1000
Com relação aos clientes aptos a receber um cupom de desconto para a próxima compra, o próximo passo seria, por exemplo, automatizar um e-mail a ser enviado para estes clientes, contendo o cupom de desconto.
Infelizmente ainda não cheguei neste nível de programação Python, além de que fiquei restrito apenas a análise dos dados neste projeto, entretanto pode ser um aspecto a ser exercitado e quem sabe apresentado em um projeto futuro.
Desta forma, acredito que foi possível apresentar o meu projeto final e demonstrar de forma breve como a programação Python pode ser fácil e intuitiva, além de ágil no momento de programar, pois com algumas poucas linhas de código é possível realizar análises interessantes para um conjunto de dados. Forte abraço!
O que aprendemos nesse artigo?
O que falam a respeito do python?
Muito tem se falado sobre a linguagem de programação “do momento” nos últimos tempos. Fácil, intuitiva, poderosa: são apenas alguns dos adjetivos encontrados para descrever a linguagem Python e suas inúmeras funcionalidades, frente a um visível crescimento em sua utilização.
O que podemos aprender no curso de python na harve?
Durante o curso aprendemos desde o mais básico - como a instalação do Python em sua máquina ou conceitos básicos de lógica de programação - até assuntos um pouco mais complexos, como o desenvolvimento web, por exemplo.
Qual é a biblioteca utilizada nesse projeto?
Como projeto final do curso, decidi optar por realizar uma breve análise de dados com a utilização da biblioteca Pandas.
O que é o site Mockaroo?
O site mockaroo.com, se trata de uma API que gera dados aleatórios em diversos formatos de arquivo, entre eles o formato CSV.
O que o comando df.info() no pandas faz?
Este comando é um método Pandas, que mostra informações do objeto data frame, incluindo o tamanho do data frame, tipo de dado de cada coluna, valores nulos, e memória usada.
Qual é a proposta dessa analise?
Encontrar o faturamento total; Encontrar a média de valor gasto pelos clientes; Selecionar as compras acima de mil dólares, para que sejam enviados cupons de desconto para as próximas compras dos respectivos clientes.
Deixe um comentário