
Conforme o mundo entrava na era do Big Data, a necessidade para o seu armazenamento destes dados também cresceu. Era o principal desafio e preocupação das empresas até 2010. O foco principal era construir uma estrutura e soluções para armazenar dados. Agora, com este problema solucionado, o foco se desviou para o processamento de dados. Data Science é o ingrediente secreto aqui. Todas essas ideias que nos quais você vê nesses filmes de Sci-fi podem na verdade se tornar realidade através do Data Science. Data Science é o futuro da inteligência artificial. Portanto, é muito importante entender o que é Data Science e como ele acrescenta valor para o seu negócio.
- O que é Data Science?
- Quem é um Cientista de Dados?
- O que um Cientista de Dados faz?
- O que é Data Science e Business Intelligence (BI)?
- O ciclo de vida do Data Science com um caso de uso
O que é Data Science?

Data Science é a combinação de várias ferramentas, algoritmos, e princípios de machine learning com o objetivo de descobrir padrões ocultos nos dados brutos. Mas como isso difere do que os estatísticos vêm fazendo há anos?
O que é data science está na diferença está entre explicar e prever.
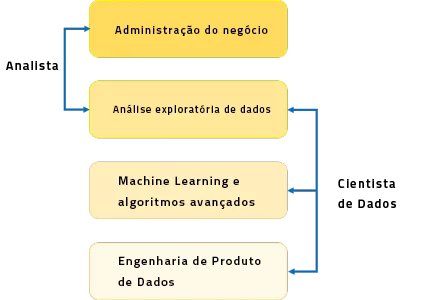
Como você pode perceber pela imagem acima, um Analista de Dados geralmente explica o que está acontecendo, processando o histórico de dados. Por outro lado, um Cientista de Dados não apenas faz a análise exploratória para descobrir insights, mas também usa vários algoritmos avançados de machine learning para identificar a ocorrência de um evento em particular no futuro. Um Cientista de Dados irá olhar para os dados por muitos ângulos, as vezes por ângulos que eram antes desconhecidos.
Então, o Data Science é a princípio utilizado para tomar decisões e fazer previsões com o uso de análises causais preditivas, análises prescritivas (ciência preditiva + decisão) e machine learning.
- Análise causal preditiva – Se você precisa de um modelo que possa prever as possibilidades de um evento em particular no futuro, você precisa aplicar a análise causal preditiva. Digamos que, se você estiver fornecendo crédito, então a probabilidade de futuramente os clientes fazerem pagamento do crédito no prazo seria motivo de preocupação para você. Aqui, você pode construir um modelo que possa realizar análises preditivas baseado no histórico de pagamento do cliente para prever se os pagamentos futuros serão pontuais ou não.
- Análise prescritiva: Se você precisa de um modelo que tenha a inteligência de tomar suas próprias decisões e a habilidade de modifica-la com parâmetros dinâmicos você certamente precisa de análise prescritiva para isso.
- Machine Learning para fazer previsões – Se você tem dados transacionais de uma empresa financeira e precisa construir um modelo para determinar as futuras tendências, então algoritmos de machine learning são a melhor aposta para isso. Isso se enquadra no paradigma de aprendizado supervisionado. É chamado de supervisionado por que você já tem os dados base nos quais o machine learning pode ser treinado. Por exemplo, um modelo de detecção de fraude pode ser treinado baseado em históricos passados de compras fraudulentas.
Vamos ver como a proporção das abordagens descritas acima diferem para entender o que é Análise de Dados e o que é Data Science. Como você pode ver nas imagens abaixo, Análise de Dados inclui análise descritiva e previsões até certo ponto. Por outro lado, Data Science é mais sobre Análise causal preditiva e machine learning.
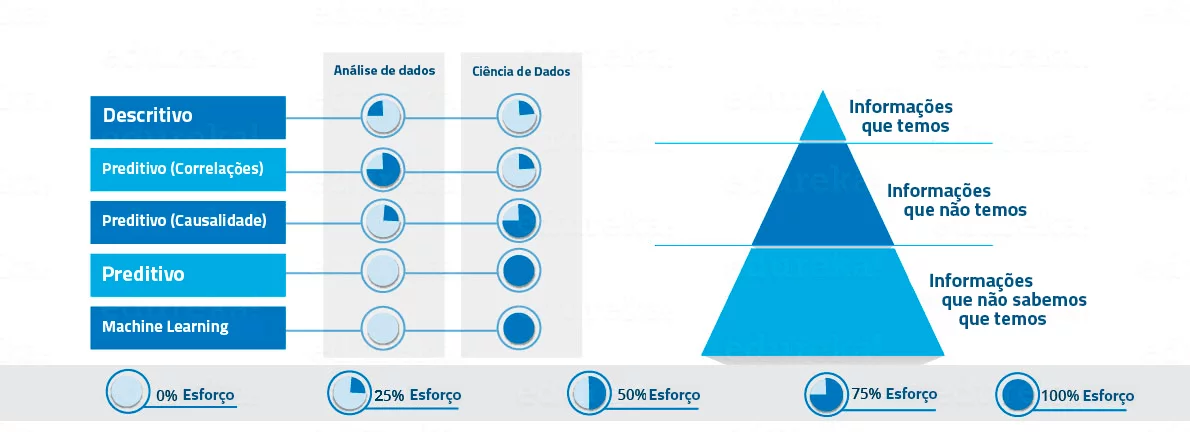
Agora que você sabe exatamente o que é Data Science. Vamos agora ver o motivo pelo qual ele é necessário.
- Tradicionalmente, os dados que nós tínhamos eram de maioria estruturados e de tamanho pequeno, que no qual poderiam ser analisados com ferramentas de BI simplórias. Diferente dos dados do sistema tradicional que no qual eram de maioria estruturados, hoje em dia a maioria dos dados são desestruturados ou semi-estruturados. Vamos dar uma olhada nas tendências de dados na imagem abaixo que nos mostra que até 2020 mais de 80% dos dados irão ser desestruturados.
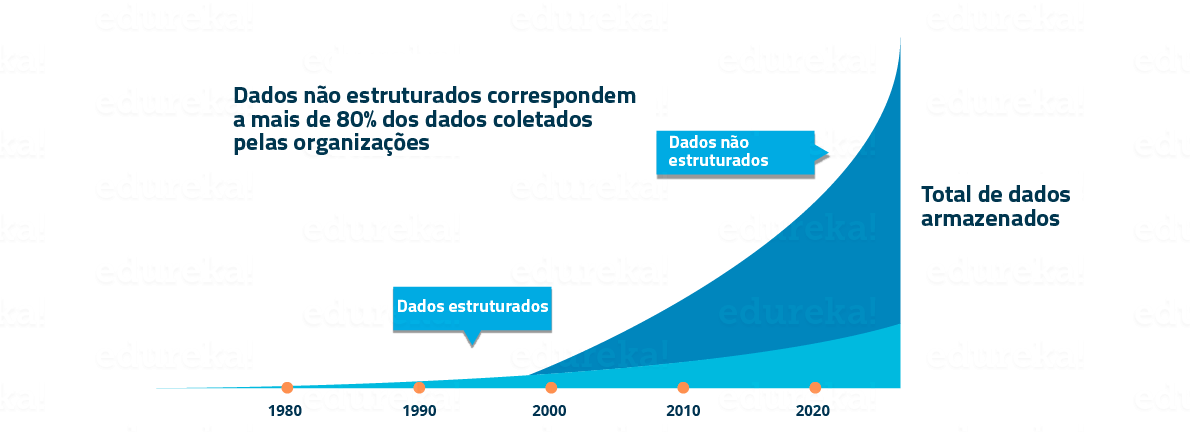
Os dados são gerados através de diferentes fontes, logs financeiros, arquivos de texto, formulários multimídia, sensores, e instrumentos. As simples ferramentas de BI não são capazes de processar esse enorme volume e variedade de dados. É por isso que precisamos de ferramentas de análise mais complexas e avançadas e algoritmos para processamento e análise para obter insights significativos.
Esse não é o único motivo pelo qual o Data Science se tornou tão popular e cada mais vezes pessoas querem saber o que é data science. Vamos cavar mais fundo e ver como o Data Science está sendo utilizado.
- Que tal se você pudesse saber precisamente os requisitos dos seus clientes através de seus dados, por exemplo, o histórico de pesquisa de seu cliente, histórico de compra, idade e salário. Sem dúvidas que você já tinha esses tipos de dados anteriormente, mas agora com uma quantidade vasta e varieda de dados, você consegue treinar modelos de forma mais eficiente e recomendar os produtos para seus clientes de forma mais precisa. Não seria incrível, pois traria mais receita para a sua empresa?
- Vamos imaginar um cenário diferente para entender o papel do Data Science nas tomadas de decisão. Que tal se o seu carro tivesse a inteligência de te dirigir até em casa como os da Tesla, carros auto-dirigíveis coletam dados em tempo real através de sensores, incluindo radares, câmeras, e lasers para criar um mapa de seus arredores. Baseado nesses dados, ele toma decisões tipo quando acelerar, quando diminuir a velocidade e quando ultrapassar um carro, e onde virar – fazendo uso de algoritmos avançados de machine learning.
- Vamos ver como o Data Science pode ser usado em análise preditiva. Vamos tomar a previsão do tempo como exemplo. Dados de navios, aeronaves, radares, satélites podem ser coletados e analisados para construir modelos. Esses modelos não somente irão prever o tempo. mas também irão ajudar a prever a ocorrência de quaisquer calamidades naturais. Irá ajudar você a tomar medidas apropriadas com antecedência e salvar a vida de muitas pessoas.
Vamos dar uma olhada no infográfico abaixo para ver as áreas onde o Data Science está se destacando.
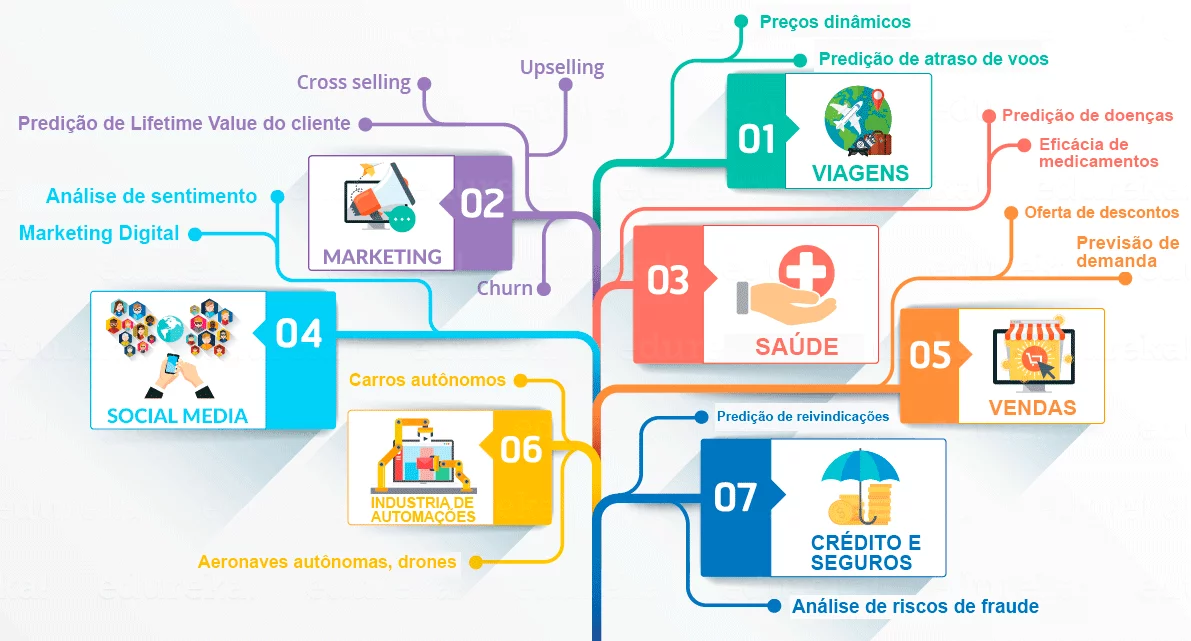
Quem é um Cientista de Dados?

Existem várias definições disponíveis para Cientistas de Dados. Em poucas palavras, um cientista de dados é aquele que pratica a arte de Data Science. O termo “Cientista de Dados” foi criado depois de considerar o fato de que um “Cientista de Dados” extrai muitas informações de aplicações e campos científicos, sejam da estatística ou matemática.
Depois que abordamos o que é data science, agora iremos abordar essa área no sentido profissional.
O que um Cientista de Dados faz?

Um Cientista de Dados é aquele que sabe o que é data science e suas implicações práticas e resolve problemas complexos de dados com sua forte expertise e certas disciplinas científicas. Eles trabalham com diversos elementos relacionados com a matemática, estatística, ciência da computação, etc (embora possam não ser especialistas em todos esses campos). Eles fazem bastante uso das últimas tecnologias para encontrar soluções e alcançar conclusões que são cruciais para o crescimento e desenvolvimento de uma organização. Cientistas de Dados apresentam os dados de uma forma muito útil, sendo eles dados brutos estruturados e não estruturados.
Vamos falar agora sobre BI. Temos certeza que você talvez já tenha ouvido falar de Business Inteligence (BI). Frequentemente o Data Science é confundido com BI. Vamos mostrar de forma clara e concisa o contraste entre os dois de forma que irão te ajudar a compreender melhor a diferença entre o que é Data Science e BI. Vamos dar uma olhada.
Em nosso outro artigo, detalhamos mais sobre a carreira de Cientista de Dados e o seu dia a dia.

O que é Data Science e Business Intelligence (BI)?
O Business Intelligence (BI) basicamente analisa o dado anterior para encontrar uma visão retrospectiva e uma visão geral para descrever tendências de negócio. Aqui o BI permite tirar dados de fontes internas e externas, preparando-os, colocando para rodar consultas e criando dashboards para responder perguntas como análise de receita trimestral ou problemas de negócio. BI consegue avaliar o impacto de certos eventos em um futuro próximo.
O que é Data Science em constraste com o BI? Data Science é uma abordagem mais voltada para o futuro, uma forma de exploração com o foco em analisar o passado e os dados atuais e de prever as consequências futuras com o objetivo de tomar decisões informadas. Ele responde perguntas abertas como “o que” e “como” os eventos ocorrem.
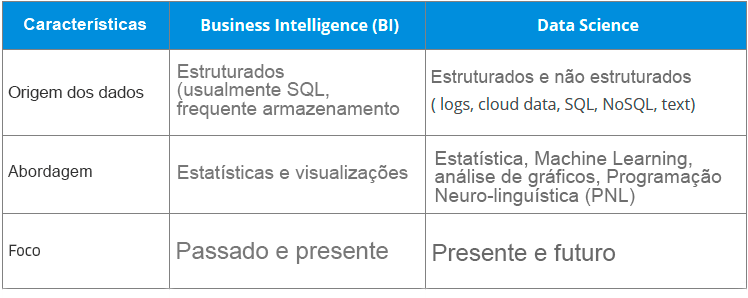
Isso é a diferença entre o que é Data Science e BI, agora vamos entender qual é o ciclo de vida do Data Science.
Um erro comum em projetos de Data Science é se apressar na análise e coleta de dados, sem compreender as exigências ou sem enquadrar o problema de negócio corretamente. Portanto, é muito importante que você acompanhe todas as fases ao longo do ciclo de vida do Data Science para garantir que o projeto dê certo.
Ciclo de vida do Data Science
Aqui está uma breve visão geral das principais fases do ciclo de vida do Data Science.
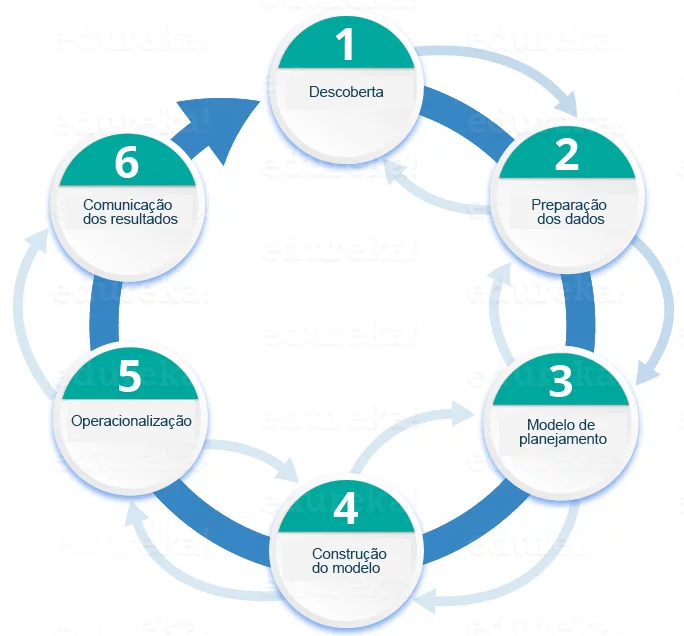
 Fase 1 — Descoberta: antes de começar o projeto, é importante entender as variadas especificações, requisitos, prioridades e orçamento necessário. Você deve possuir a habilidade de fazer as perguntas certas. Aqui você avalia se você tem os recursos necessários em mãos em termos de pessoas, tecnologia, tempo e dados para auxiliar o projeto. Nesta fase você também precisa enquadrar o problema de negócio e formular hipóteses iniciais ou Initial Hipothesis (IH) para testar.
Fase 1 — Descoberta: antes de começar o projeto, é importante entender as variadas especificações, requisitos, prioridades e orçamento necessário. Você deve possuir a habilidade de fazer as perguntas certas. Aqui você avalia se você tem os recursos necessários em mãos em termos de pessoas, tecnologia, tempo e dados para auxiliar o projeto. Nesta fase você também precisa enquadrar o problema de negócio e formular hipóteses iniciais ou Initial Hipothesis (IH) para testar.
 Fase 2 — Preparação dos dados: nessa fase, você precisa de um sandbox analítico na qual pode realizar análises durante toda a duração do projeto. Você precisa explorar, pré-processar e condicionar o dado antes da modelagem. Além disso, você irá realizar o ETLT (extract, transform, load and transform) para colocar dados no Sandbox. Vamos dar uma olhada no fluxo de análise estatística abaixo.
Fase 2 — Preparação dos dados: nessa fase, você precisa de um sandbox analítico na qual pode realizar análises durante toda a duração do projeto. Você precisa explorar, pré-processar e condicionar o dado antes da modelagem. Além disso, você irá realizar o ETLT (extract, transform, load and transform) para colocar dados no Sandbox. Vamos dar uma olhada no fluxo de análise estatística abaixo.

Você pode usar o Python para limpeza de dados, transformação, e visualização, isso irá te ajudar a identificar e estabelecer uma relação entre as variáveis. Uma vez que você limpou e preparou os dados, é hora de fazer análise exploratória, vamos ver como você consegue fazer isso.
 Fase 3 — Planejamento de modelo: Aqui, você irá determinar os métodos e técnicas para traçar as relações entre as variáveis. Essas relações irão determinar a base para os algoritmos, no qual você irá implementar na próxima fase. Você irá aplicar a análise de dados exploratório (EDA) usando ferramentas de visualização e várias fórmulas estatísticas.
Fase 3 — Planejamento de modelo: Aqui, você irá determinar os métodos e técnicas para traçar as relações entre as variáveis. Essas relações irão determinar a base para os algoritmos, no qual você irá implementar na próxima fase. Você irá aplicar a análise de dados exploratório (EDA) usando ferramentas de visualização e várias fórmulas estatísticas.
Vamos dar uma olhada nas ferramentas de planejamento de modelo.

- Python tem um conjunto completo de capacidades de modelagem e tem bons ambientes para construção de modelos interpretativos.
- Os Serviços de Análises SQL podem realizar análises no banco de dados usando funções comuns de mineração de dados e modelos preditivos básicos.
- SAS/ACCESS pode ser usado para acessar dados do hadoop e é usado para criar fluxo de modelos de diagramas reutilizáveis e repetíveis.
Agora que você tem insights sobre a natureza dos seus dados e decidiu quais algoritmos a serem usados, no próximo passo, você irá aplicar o algoritmo e construir um modelo.
 Fase 4 — Construção de modelo: Nesta etapa você, você irá desenvolver conjuntos de dados para fins de treinamento e teste. Aqui, você precisa considerar se as suas ferramentas existentes serão suficientes para executar os modelos ou irá precisar de um ambiente mais robusto (como processamento paralelo e rápido). Você irá analisar várias técnicas de aprendizado como classificação, associação e clustering para construir os modelos.
Fase 4 — Construção de modelo: Nesta etapa você, você irá desenvolver conjuntos de dados para fins de treinamento e teste. Aqui, você precisa considerar se as suas ferramentas existentes serão suficientes para executar os modelos ou irá precisar de um ambiente mais robusto (como processamento paralelo e rápido). Você irá analisar várias técnicas de aprendizado como classificação, associação e clustering para construir os modelos.
Você pode alcançar a construção de modelo através das seguintes ferramentas.
 Fase 5 — Operacionalize: Nesta fase, você entrega relatórios finais, briefings, documentos de programação e técnicos. Além disso, às vezes um projeto piloto é implementado em um ambiente de produção em tempo real. Isso irá te dar uma visão clara da performance e de outras restrições a respeito em uma escala menor antes da implantação completa.
Fase 5 — Operacionalize: Nesta fase, você entrega relatórios finais, briefings, documentos de programação e técnicos. Além disso, às vezes um projeto piloto é implementado em um ambiente de produção em tempo real. Isso irá te dar uma visão clara da performance e de outras restrições a respeito em uma escala menor antes da implantação completa.
 Fase 6 — Comunique os resultados: Agora, é importante avaliar se você tem sido capaz de alcançar seu objetivo que você planejou na primeira fase. Então, na fase final, você identifica todas as descobertas chave, comunica para o stakeholders e determina se os resultados do projeto são um sucesso ou um fracasso baseados no critério desenvolvido na fase 1.
Fase 6 — Comunique os resultados: Agora, é importante avaliar se você tem sido capaz de alcançar seu objetivo que você planejou na primeira fase. Então, na fase final, você identifica todas as descobertas chave, comunica para o stakeholders e determina se os resultados do projeto são um sucesso ou um fracasso baseados no critério desenvolvido na fase 1.
Agora, eu vou pegar um caso de estudo para explicar todas as fases descritas acima.
Caso de estudo: Prevenção de diabetes.
Vamos ver na prática o que é data science no contexto de ciclo de vida:
Se nós pudéssemos prever a ocorrência de diabetes e tomássemos medidas apropriadas com antecedência para prevenir-se?
Nesse caso, nós iremos prever a ocorrência fazendo uso inteiramente do ciclo de vida que nós discutimos mais cedo. Vamos percorrer as várias etapas.
Passo 1:
- Primeiro, nós iremos coletar os dados baseado no histórico médico do paciente como foi discutido na Fase 1. Você pode referir a amostra de dados abaixo.
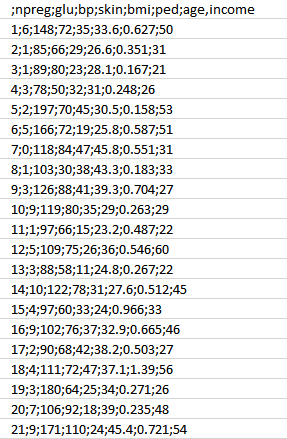
Como você pode ver, nós temos os vários atributos, como podemos ver abaixo:
Atributos:
- npreg — Número de vezes gravida
- glicose — Concentração de glicose plasmática
- bp — Pressão sanguínea
- skin — Espessura da dobra cutânea do tríceps
- bmi — Índice de massa corporal
- ped — Diabetes Pedigree Function (DPF) (Tendência genética em desenvolver diabetes)
- age — Idade
- income — Renda
Passo 2:
- Agora, uma vez que temos os dados, nós precisamos limpar e preparar os dados para análise de dados.
- Esses dados possuem muitas inconsistências tais como valores faltantes, colunas brancas, valores exagerados e formato incorreto de dados, nos quais precisam ser limpados.
- Aqui, nós organizamos os dados em uma única coluna sob diferentes atributos – fazendo parecer mais estruturado.
- Vamos dar uma olhada na amostra de dados abaixo.

Esses dados possuem muitas inconsistências
- Na coluna npreg, “one” está escrito por extenso, onde deveria estar com caractere numérico tipo “1”.
- Na coluna bp um dos valores está exagerado “6600” que no qual é impossível (pelo menos para humanos) pois o bp não pode ir para um valor tão alto assim.
- Como você pode ver, a coluna de Renda está branco e também não faz sentido nenhum para prever a diabetes. Portanto, é redundante tê-lo, e deveria ser removido da tabela.
- Então, nós iremos limpar e pré-processar esse dado removendo os outliers, preenchendo os valores null e normalizando os tipos de dados. Não sei se você se lembra, mas essa é a nossa segunda fase no qual é chamado de pré-processamento de dados.
- Finalmente, nós temos o dado limpo como é mostrado abaixo que no qual pode ser então utilizado para ser analisado.
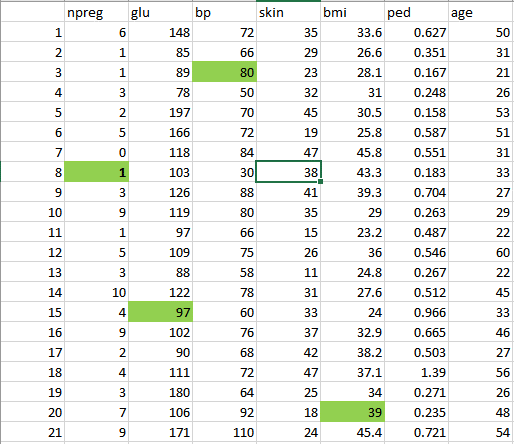
Passo 3:
Agora, vamos fazer uma análise, conforme foi falado anteriormente na Fase 3
- Primeiro, nós iremos carregar os dados no sandbox de análise e aplicar várias funções estatísticas. Por exemplo, R tem funções como “descrever” o qual nos dá o número de valores faltantes e valores únicos. Nós também podemos utilizar a função de resumo que nos dará informações estatísticas tais como mean, median, range, e valores min e max.
- Então, nós utilizamos técnicas de visualização tipo histogramas, gráficos de linha, diagramas de caixa para ter uma visão clara da distribuição de dados.
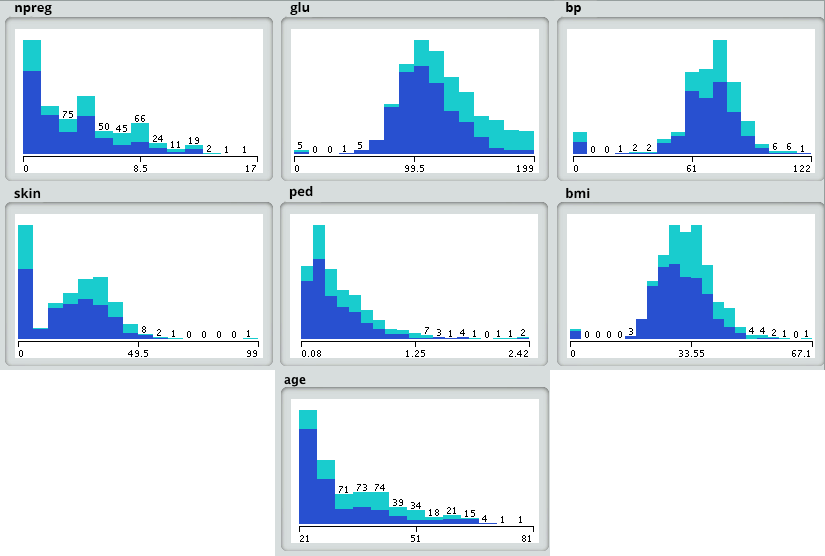
Passo 4: agora baseado em insights derivados do passo anterior, a melhor solução para esse tipo de problema é a árvore de decisão. Vamos ver como?
- Visto que já temos os maiores atributos para análise tipo npreg, bmi, etc. Então nós utilizaremos a técnica de aprendizado supervisionado para construir um modelo aqui.
- Além disso, nós utilizamos particularmente a árvore de decisão porque ele pega todos os atributos de uma vez só, tipo os que têm um relacionamento linear e também aqueles que têm um relacionamento não linear. Em nosso caso, nós temos uma relacionamento linear entre npreg e age, em contrapartida do relacionamento não linear entre npreg e ped.
- Modelos de árvores de decisão são também bem robustos pois podemos utilizar diferentes combinações de atributos para fazer várias árvores e então finalmente implementar a que tem a máxima eficiência.
Vamos dar uma olhada na nossa árvore de decisão.
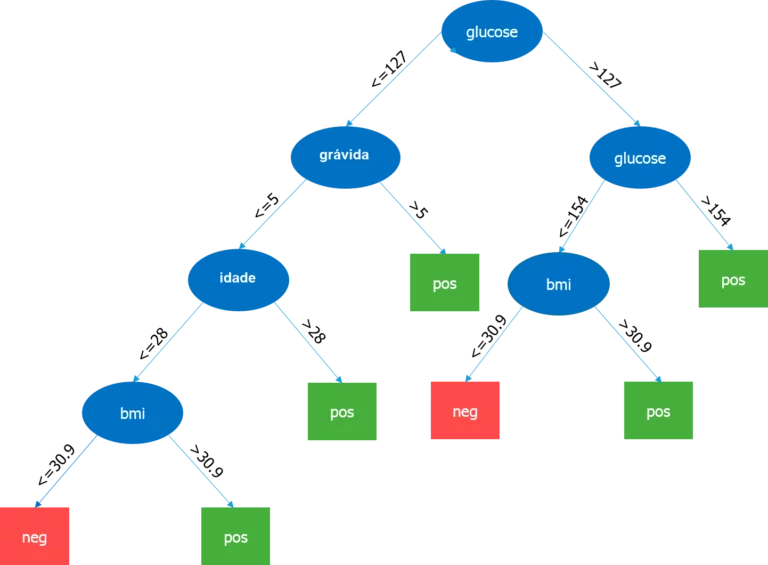
Aqui o parâmetro mais importante é o nível de glicose, portanto, é o nosso root node (nó raiz). Agora, o node atual e seu valor determinam o próximo parâmetro importante a ser usado. Isso continua até que a gente consiga o resultado em termos de pos e neg. Pos significa que a tendência de ter diabetes é positiva e neg significa que a tendência de ter diabetes é negativa.
Passo 5: Nessa fase, nós rodaremos um pequeno projeto piloto para checar se nossos resultados são apropriados. Nós também olharemos por restrições de desempenhos, se caso tiver alguma. Se os resultados não forem precisos, então nós teremos que replanejar e reconstruir o modelo.
Passo 6: Uma vez que a gente tenha executado o projeto com sucesso, nós compartilharemos o output para implantação completa.
Ser um Cientista de Dados é mais fácil falar do que fazer. Então agora falamos o que é data science e o que é um cientista de dados, vamos ver tudo o que você precisa para ser um. Ser um cientista de dados requer habilidades de três grandes áreas como é mostrado abaixo.
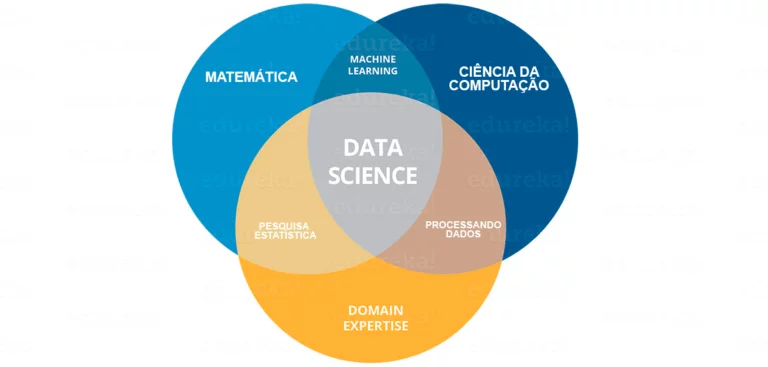
Como você pode ver na imagem acima, você precisa obter vários hard skills e soft skills. Você precisa ser bom em estatística e matemática para analisar e visualizar dados. Também, você precisa ter uma compreensão sólida da empresa que você está trabalhando para entender os problemas claramente, não somente saber o que é data science e suas habilidades. Sua tarefa não termina aqui. Você deve ser bom em implementar vários algoritmos que no qual exigem boas habilidades de programação. Finalmente, uma vez que você tenha feito certas decisões chaves, é importante que você as entregue para os stakeholders. Então, ter uma boa comunicação te dará uma vantagem extra. Tudo isso compõe o que é data science.
Este artigo “O que é Data Science? Um guia para iniciantes” foi adaptado e inspirado de: Edureka
O que aprendemos neste artigo?
O que é Data Science?
Data Science é a combinação de várias ferramentas, algoritmos, e princípios de machine learning com o objetivo de descobrir padrões ocultos nos dados brutos.
Quem é o Cientista de dados?
Existem várias definições disponíveis para Cientistas de Dados. Em poucas palavras, um cientista de dados é aquele que pratica a arte de Data Science.
O que um cientista de dados faz?
Um Cientista de Dados é aquele que sabe o que é data science e suas implicações práticas e resolve problemas complexos de dados com sua forte expertise e certas disciplinas científicas.
O que é Business Intelligence?
Business Intelligence (BI) basicamente analisa o dado anterior para encontrar uma visão retrospectiva e uma visão geral para descrever tendências de negócio.
O que é Data Science em comparação com o Business intelligence?
O que é Data Science em constraste com BI? Data Science é uma abordagem mais voltada para o futuro, uma forma de exploração com o foco em analisar o passado e os dados atuais e de prever as consequências futuras com o objetivo de tomar decisões informadas.
Deixe um comentário