
O que é o Machine Learning? O Machine Learning (abreviado também como ML) é uma aplicação da inteligência artificial (AI) que permite com que dispositivos aprendam através de experiência própria e se auto-melhorem sem precisar codar. Por exemplo, quando você faz uma compra de qualquer site, alguns sites te mostram buscas relacionadas ao que você comprou, e isso foi automático, sem que um programador tivesse que programar suas preferências
Tabela de conteúdos:
- Machine learning: o que é?
- Porque deveriamos aprender Machine Learning?
- Como começar com o Machine Learning?
- Os 7 passos do Machine Learning
- Como funciona o Machine Learning?
- Qual a melhor linguagem de programação para Machine Learning?
- A diferença entre Machine Learning e Inteligência Artificial
- Tipos de Machine Learning
- Aplicações do Machine Learning
- FAQs
Machine Learning: o que é?
Arthur Samuel criou o termo Machine Learning (aprendizado de máquina) em 1959. Ele foi pioneiro na inteligência artificial e jogos de computador, e definiu Machine Learning como “Um campo de estudos que dá capacidade de aprendizado para computadores sem precisar programar”.
Nesse artigo, primeiramente, iremos discutir detalhes sobre o que é o Machine Learning, e cobriremos diversos aspectos como, processos e aplicações. E depois, nós falaremos sobre a importância do Machine Learning. Iremos explicar os termos que são utilizados no Machine Learning e o passo a passo de uma abordagem Machine Learning. Mais a frente, iremos também entender a base do Machine Learning e como funciona. Mais ainda, falaremos o porque o Python é a melhor linguagem para Machine Learning. E finalmente iremos falar das diversas abordagens de Machine Learning e suas aplicações na indústria.
Voltando ao assunto sobre o que é o Machine Learning. O Machine Learning é uma subcategoria da inteligência artificial. O Machine Learning é o estudo sobre transformar máquinas parecidas com os seres humanos em seus comportamentos e decisões dando a eles a habilidade de aprender e desenvolver seus próprios programas. Isso tudo é feito com pouca intervenção humana, em outras palavras, sem ter algo explicitamente progamado. O processo de aprendizagem é automatizado e melhorado baseado na experiência da máquina. Durante seu processo, dados de boa qualidade são alimentados à máquina, e diferentes algoritmos são utilizados para criar modelos de machine learning para treinar as máquinas nesses dados. A escolha do algoritmo depende do tipo de dado em mãos, e o tipo de atividade que precisa ser automatizada.
Agora você talvez se pergunte, como isso difere da programação tradicional? Bom, na programação tradicional, nós alimentamos o dado de input e um programa bem codado e testado na máquina para gerar um output. Quando falamos de Machine Learning, o dado de input junto com o dado de output são alimentados na máquina durante a fase de aprendizagem, e ele irá criar um programa pra si mesmo. Para compreender isso melhor sobre o que é o Machine Learning, dê uma olhada na ilustração abaixo.
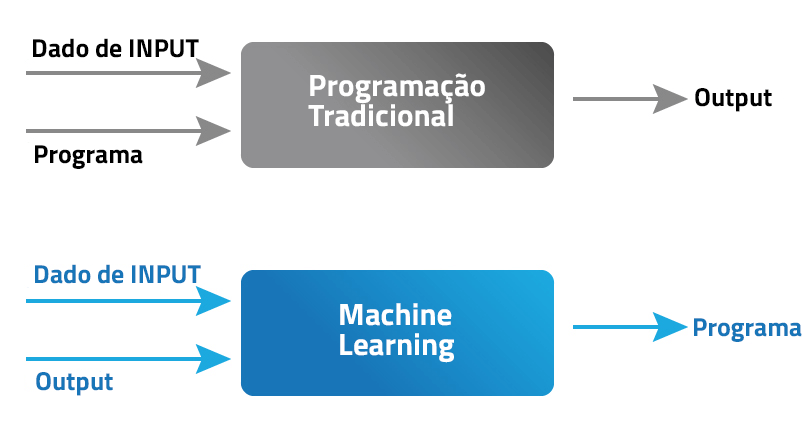
Agora que você sabe sobre o que é o Machine Learning, você talvez se pergunte, porque eu devo aprender isso? Continue lendo para descobrir!
Porque deveríamos aprender Machine Learning?
O Machine Learning hoje em dia está chamando muita atenção. O Machine Learning consegue automatizar muitas tarefas, especialmente aquelas tarefas que somente humanos conseguem fazer com sua inteligência. Replicar essa inteligência para as máquinas só pode ser concebida com a ajuda do Machine Learning.
Com a ajuda do Machine Learning, as empresas conseguem automatizar tarefas de rotina. Também ajuda na automação e rápida criação de modelos para análise de dados. Muitas empresas dependem de enormes quantidades de dados para otimizar suas operações e tomar decisões inteligentes. O Machine Learning ajuda na criação de modelos que conseguem processar e analisar grandes quantidades de dados complexos para entregar resultados precisos. Esses modelos são precisos e escaláveis e funcionam com pouco delay. Ao criar modelos de Machine Learning tão precisos, as empresas conseguem alavancar oportunidades lucrativas e evitar riscos desconhecidos.
Um reconhecimento de imagem, gerador de textos e muitos outros usos de caso do Machine Learning estão sendo utilizados no mundo real. Isso está tornando os profissionais de Machine Learning bastante procurados.
Não se contente em saber somente sobre o que é o Machine Learning, e porque deveríamos aprender, continue lendo para saber mais a fundo e na prática como funciona o Machine Learning.
Como começar com o Machine Learning?

Você talvez tenha se interessado e queira ir mais adiante ao ponto de querer começar com o ML, Então antes de saber como começar vamos primeiro dar uma olhada em terminologias importantes dentro do Machine Learning:
Algumas terminologias dentro do Machine Learning
- Model (modelo): Também conhecido como “Hipotese”, um modelo de Machine Learning é a representação matemática de um processo do mundo real. Um algoritmo de Machine Learning junto com os dados de treinamento constrói um modelo de Machine Learning.
- Feature (recurso): Um feature é uma propriedade mensurável ou parâmetro do conjunto de dados.
- Feature Vector (recurso de vetor): É um conjunto de features (recursos) numéricos. Nós utilizamos como input do modelo de machine learning para propósitos de treinamento e predição.
- Training (treinamento): O algoritmo pega um conjunto de dados denominados como “training data” (dados de treinamento) como input. O algoritmo de aprendizado encontra padrões nos dados de input e treina os modelos para resultados esperados (target). O output do processo de treinamento é o modelo de machine learning.
- Prediction (predição): Uma vez que o modelo de machine learning está preparado, ele pode ser alimentado com dados input para fornecer o output previsto.
- Target (Label): O valor que o modelo de machine learning tem que aprender é chamado de target ou label.
- Overfitting: Quando uma grande quantidade de dados treina um modelo de machine learning, ele tende a aprender do ruído e dos dados de input imprecisos. Aqui o modelo falha em caractegorizar o dado corretamente.
- Underfitting: É o cenário onde o modelo falha em decifrar a tendência implícita dos dados de input. Ele destrói a precisão do modelo de machine learning. Em termos mais simples, o modelo ou o algoritmo não se encaixa com o dado perfeitamente.
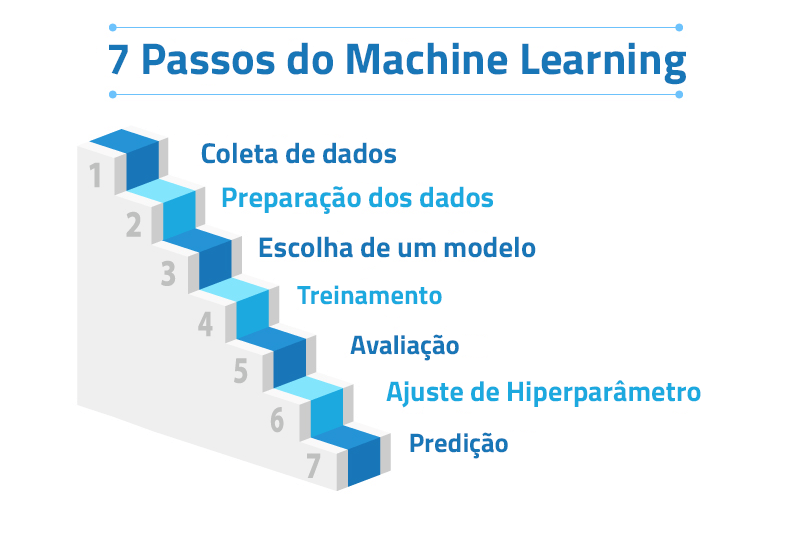
Existem 7 passos do Machine Learning
- Coleta de dados
2. Preparação dos dados
3. Escolha de um modelo
4. Treinamento
5. Avaliação
6. Ajuste de hiperparâmetro
7. Predição
É obrigatório que você aprenda uma linguagem de programação, preferencialmente o Python, juntamente com o conhecimento analítico de matemática exigido. Aqui embaixo temos as 3 áreas da matemática que você precisa dominar antes de começar a resolver problemas de machine learning.
- Algebra linear para análise de dados: Escalares, Vetores, Matrizes e tensores
- Análise matemática: derivativos e gradientes
- Teoria probabilística e estatística
- Cálculo multivariado
- Algoritmos e otimizações complexas
Como funciona o Machine Learning?
As três bases de um sistema de Machine Learning são o modelo, os parâmetros e o aluno.
- O modelo é o sistema que faz as predições
- Os parâmetros são os fatores que são considerados pelo modelo para fazer predições
- O aluno faz os ajustes nos parâmetros e modelos para alinhar as predições com os resultados
Vamos construir usando como exemplo dois objetos, o vinho e a cerveja, para entender o que é e como funciona o Machine Learning. Vamos supor que o modelo de machine learning aqui tem que prever se uma bebida é cerveja ou um vinho. Os parâmetros selecionados são as cores da bebida e a porcentagem de álcool. O primeiro passo é:
Aprender do conjunto de treinamento
Isso envolve pegar uma amostra de conjunto de dados de várias bebidas para cada cor e porcentagem de álcool especificada. Agora, nós precisamos definir a descrição de cada classificação, que seja cerveja e vinho, em termos do valor do parâmetro para cada tipo. O modelo pode utilizar a descrição para decidir se uma nova bebida é cerveja ou vinho.
Você pode representar os valores dos parâmetros, ‘cor’ e ‘porcentagem de álcool’ como ‘x’ e ‘y’ respectivamente. Então (x,y) define os parâmetros de cada drink dos dados treinados. Esse conjunto de dados é chamado de conjunto de treinamento. Esses valores, quando exibidos em um gráfico, apresenta uma hipótese na forma de uma linha, um retângulo ou polinomial que encaixa melhor para os resultados desejados.
O segundo passo é medir o erro
Uma vez que o modelo está treinado em um conjunto de dados definido, ele precisa ser checado pra ver se não tem discrepâncias ou erros. Nós utilizamos um conjunto de dados frescos para desempenhar esta tarefa. O resultado desse teste deve ser um desses quatro:
- True Positive (Verdadeiro Positivo): Quando o modelo prevê a condição quando está presente
- True Negative (Verdadeiro Negativo): Quando o modelo não prevê uma condição quando ela está ausente
- False Positive (Falso Positivo): Quando o modelo prevê a condição quando está ausente
- False negative (Falso Negativo): Quando o modelo não prevê uma condição quando está presente
A soma do FP e FN e o erro total do modelo
Gerenciamento de ruído
Para fins de simplicidade, nós consideramos somente dois parâmetros para abordar esse problema de machine learning que é a coloração e e a porcentagem de alcool. Mas na realidade, você irá precisar considerar centenas de parâmetros e um grande conjunto de dados de aprendizado para solucionar um problema de machine learning.
A hipótese criada terá muitos mais erros por causa do ruído. Ruídos são anomalias indesejadas que atrapalham o conjunto de dados e enfraquece o processo de aprendizagem. Os motivos do porquê isso ocorre são:
- Grande conjunto de dados de treinamento
- Erros nos dados de input
- Erros na rotulagem dos dados
- Atributos não observados que talvez afetem a classificação, mas não são considerados dentro do conjunto de dados por falta de dados
Você pode aceitar um certo nível de erro de treinamento por causa de ruído para manter a hipótese o mais simples possível
Teste e generalização
Enquanto que é possível que um algoritmo ou hipótese se encaixe bem em um conjunto de treinamento, ele talvez falhe quando aplicado a outro conjunto de dados fora do conjunto de treinamento. Portanto, é importante descobrir se o algoritmo serve para os novos dados. Testá-lo com um novo conjunto de novos dados é uma forma de julgar isso. Também, generalização se refere a quão bem o modelo prevê resultados para um novo conjunto de dados.
Quando encaixamos um algoritmo de hipótese para que tenha o máximo de simplicidade, talvez tenha menos erros para os dados de treinamento, mas talvez tenha erros mais significantes enquanto processa novos erros. Nós chamamos isso de underfitting. Por outro lado, se a hipótese for muito complicada para acomodar o melhor ajuste para os resultados de treinamento, talvez ele não se generalize tão bem. Esse é um caso de overfitting. Em ambos os casos, os resultados são retroalimentados para treinar mais o modelo.
Agora já sabemos sobre Machine Learning, terminologias, como funciona, como começar, etc. Continue lendo para descobrir as linguagens mais utilizadas na área.
Qual a melhor linguagem de programação para Machine Learning
O Python é sem dúvida a melhor linguagem para aplicações Machine Learning devido aos inúmeros benefícios citados ali embaixo. Outras linguagens que também podem ser utilizadas para o Machine Learning são o R, C++, Java, C#, Julia, Shell, TypeScript e Scala.
O Python é famoso por ser fácil de ser lido e possuir pouca complexidade se comparado às outras linguagens de programação. Aplicações de Machine Learning envolvem conceitos complexos como cálculo e álgebra linear que tomam muito esforço e tempo para implementar. O Python serve para reduzir este fardo dando ao engenheiro de machine learning a capacidade de implementar rapidamente as ideias para serem validadas. Um outro benefício de se usar o Python no Machine Learning são as bibliotecas pré-construídas. Existem diferentes pacotes para diferentes tipos de aplicações.
- Numpy, OpenCV e Scikit são utilizados para se trabalhar com imagens
- NLTK junto com o Numpy e Scikit novamente quando trabalha-se com textos
- Librosa para aplicações de áudio
- Matplotlib, Seaborn e Scikit para apresentação de dados
- TensorFlow e Pytorch para aplicações de Deep Learning
- Scipy para computação científica
- Django para integração de aplicações web
- Pandas para estruturas de dados de alto nível e análise
Python é uma linguagem de programação versátil e funciona em qualquer plataforma, incluindo Windows, MacOS, Linux, Unix e outros. Caso você migre de uma plataforma para outra, o código irá precisar de pequenas adaptações e mudanças e fazendo isso estará pronto para funcionar na nova plataforma.
Saiba mais sobre versatilidade e facilidade do Python com esse vídeo:
CURSO PYTHON COMPLETO E GRATUITO - APRENDA AGORA
Aqui embaixo temos um resumo do porque utilizar python para problemas de machine learning.

A diferença entre Machine Learning e Inteligência Artificial
Ao se perguntar sobre Machine Learning, é comum também perguntar a respeito da IA e se são a mesma coisa, bom, a IA gerencia questões mais abrangentes de automação de um sistema utilizando campos como ciência cognitiva, processamento de imagem, machine learning ou redes neurais para computação. Por outro lado, o ML faz com que a máquina aprenda de um ambiente externo. O ambiente externo pode ser qualquer coisa como dispositivos de armazenamento externo, sensores, segmentos eletrônicos, etc.
A inteligência artificial permite também que máquinas e frameworks pensem e façam tarefas como um humano faria. Enquanto que o Machine Learning depende dos inputs fornecidos ou buscas feitas pelos usuários. O framework atua no input rastreando se ela está disponível na base de conhecimento, e em seguida, fornece o output.
Tipos de Machine Learning
Nessa seção, iremos falar sobre as diferentes abordagens de machine learning e a variedade de problemas que eles conseguem resolver.
O que é aprendizado supervisionado?
O aprendizado supervisionado possui uma série de variáveis de inputs (x), e uma variável de output (y). Um algoritmo identifica a função de mapeamento entre as variáveis de input e output. A relação é y = f(x).
O aprendizado é monitorado ou supervisionado no sentido de que já conhecemos a output e o algoritmo é corrigido cada vez para otimizar seus resultados. O algoritmo treina em cima do conjunto de dados, e corrigido até que atinja um nível aceitável de performance.
Nós podemos agrupar o aprendizado supervisionado como:
- Problemas de regressão – Utilizado para prever valores futuros e o dado é treinado com dados históricos. Por exemplo, prever o futuro preço de um produto.
- Problemas de classificação – Várias marcas treinam o algoritmo para identificar itens dentro de uma categoria específica. Por exemplo, Doença ou não doença, Maçã ou uma laranja, Vinho ou cerveja.
O que é aprendizado não supervisionado?
Essa abordagem é aquela onde o output é desconhecido, e nós só temos a variável de input em mãos. O algoritmo aprende sozinho e descobre uma estrutura impressionante nos dados.
A ideia é decifrar a distribuição implícita nos dados para conseguir mais conhecimento a respeito do dado.
Nós podemos agrupar os problemas de aprendizado não supervisionado como:
- Clustering: Isso significa agrupar juntas as variáveis de input com as mesmas características. Ex: agrupar usuários baseado no histórico de pesquisa.
- Associação: Aqui, nós descobrimos como associar de forma inteligente dados entre um conjunto de dados. Ex: pessoas que assistem “x” irão provavelmente assistir “y”.
O que é aprendizado semi-supervisionado?
Em aprendizado semi-supervisionado, treinam um modelo com o mínimo de dados rotulados (labelled) e uma grande quantidade de dados não rotulados. Geralmente, o primeiro passo é amontoar dados similares com a ajuda de um algoritmo de machine learning não supervisionado. O próximo passo é rotular o dado não rotulado utilizando características dos dados rotulados que estão disponíveis. Após rotular o dado completamente, agora você pode utilizar algoritmos de aprendizado supervisionado para resolver o problema.
O que é aprendizado por reforço?
Nesta abordagem, modelos de machine learning são treinados para tomar uma série de decisões baseadas em recompensas e feedbacks que recebem por suas ações. A máquina aprende a atingir um objetivo em situações complexas e incertas e é recompensada toda vez que atinge o objetivo durante o período de aprendizado.
Reinforcement Learning (aprendizado por reforço) é diferente do aprendizado supervisionado com a diferença de que não existe resposta disponível, então o agente de reforço decide os passos para desempenhar uma tarefa. A máquina aprende por experiência própria quando não existe conjunto de dados de treinamento presente.
Os algoritmos de machine learning ajudam a construir sistemas inteligentes que conseguem aprender de suas experiências passadas e dados históricos para dar resultados precisos. Muitas empresas estão aplicando soluções de machine learning para resolver os seus problemas de negócio, ou também criar melhores produtos e serviços. A saúde, defesa, serviços financeiros, marketing e serviços de segurança, etc, utilizam o machine learning em seus processos.
Agora que sabemos desde o ML até sua diferença entre AI, vamos ver suas aplicações nos setores.
Aplicações do Machine Learning

Reconhecimento facial/imagem
O uso mais comum de machine learning é para reconhecimento facial, e o exemplo mais simples disso é o Iphone X. Existem vários casos de uso de reconhecimento facial, a maioria é com propósitos de segurança tipo identificação de criminosos, procura por pessoas que estão desaparecidas, para ajudar investigações forenses, etc. Marketing inteligente, diagnosticar doenças, acompanhar frequências de presença nas escolas, são outros tipos de usos.
Reconhecimento automático de discurso
Abreviado como ASR, Automatic Speech Recognition é utilizado para converter um discurso em texto. Sua aplicação se resume em autenticar os usuários baseado na sua voz e desempenhar tarefas baseado nos inputs de voz das pessoas. Padrões de discurso e vocabulário são alimentados no sistema para treinar o modelo. Atualmente sistemas ASR encontram uma grande variedade de aplicações nos seguintes domínios:
- Assistência médica
- Robótica Industrial
- Forense e aplicação na lei
- Defesa & Aviação
- Indústria de telecomunicações
- Automações em casa e controle de acesso de segurança
- TI e eletrônicos de consumo
Serviços Financeiros
O Machine Learning possui muita utilidade para com serviços financeiros. Algoritmos de Machine Learning se provaram serem bastante úteis para detecção de fraudes ao monitorar as atividades de cada usuário avaliando se uma tentativa de atividade é típica daquele usuário ou não. Monitoramento financeiro para detectar lavagem de dinheiro também é um uso do Machine Learning para segurança.
O Machine Learning também ajuda a tomar melhores decisões de troca com a ajuda de algoritmos que conseguem analisar milhares de dados simultaneamente. Os scores de cartões de créditos e subscrição são outras das outras aplicações do Machine Learning.
A aplicação mais comum no nosso dia-a-dia são as assistentes virtuais Siri e Alexa.
Marketing e Vendas
O machine learning tem ajudado com algoritmos de pontuação de leads ao incluir vários parâmetros, tais como, visitas ao website, emails abertos, downloads e cliques, tudo isso para definir a pontuação de cada leads e sua qualidade. Também ajuda negócios a definir seus modelos de preços dinâmicos utilizando técnicas de regressão para fazer previsões.
Análise de sentimento é uma outra ótima aplicação para avaliar a resposta do consumidor a um produto específico ou iniciativa de marketing. Machine learning para Computer Vision ajuda as empresas a identificarem seus produtos em vídeos e imagens online. As empresas também utilizam computer vision para checar menções que eles não sabem sobre sua marca. Os chatbots também tem se tornado mais responsivos e inteligentes com a ajuda do Machine Learning.
Saúde
Uma aplicação importante do machine learning é na detecção de doenças e enfermidades, no qual sem ela seriam difíceis de serem diagnosticadas. A radioterapia também tem melhorado bastante com o machine learning.
A descoberta de medicamentos em estágio inicial é uma outra aplicação bastante crucial do Machine Learning que envolve medicina de precisão e sequenciamento de próxima geração. Esses ensaios clínicos custam muito tempo e dinheiro para se completar e entregar resultados. Aplicar machine learning baseado em análise de predição podem melhorar esses fatores e dar melhores resultados.
Aplicações do Machine Learning também são importantes para prever surtos. Os cientistas no mundo inteiro estão utilizando o Machine Learning para prever surtos.
Sistemas de recomendação
Muitas empresas hoje em dia utilizam sistemas de recomendação para se comunicarem melhor com seus usuários em seus sites. Elas conseguem recomendar produtos, filmes, séries, sons relevantes e muito mais. Os lugares onde mais se utilizam essas tecnologias são em e-commerces tipo a Amazon, Flipkart, e muitos outros, juntamente do Spotify, Netflix, e outros sites de streaming em tempo real.
Agora que lemos sobre o que é o Machine Learning, vamos dar uma refrescada na memória com esse resumo abaixo.
Artigo adaptado e inspirado de: https://www.mygreatlearning.com/blog/what-is-machine-learning/
O que aprendemos nesse artigo?
O que é Machine Learning?
O Machine Learning é o estudo sobre transformar máquinas parecidas com os seres humanos em seus comportamentos e decisões dando a eles a habilidade de aprender e desenvolver seus próprios programas.
Onde é utilizado o Machine Learning?
É utilizando em várias áreas, sendo algumas, reconhecimento facial, carros auto-dirigiveis, assistentes virtuais, recomendação de produtos, etc.
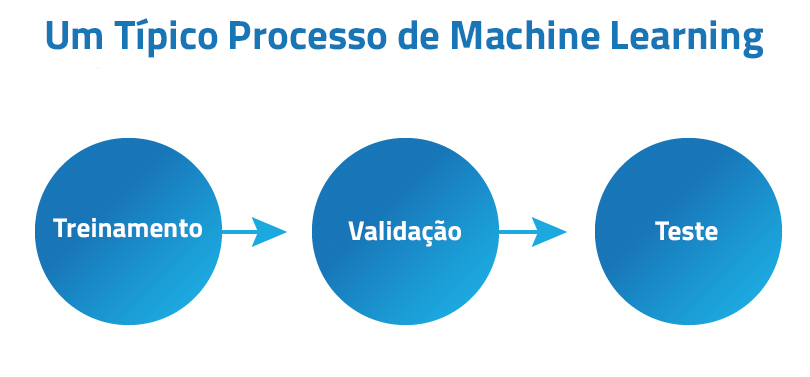
Como é o processo de Machine Learning?
O processo típico de Machine Learning se resume em 3 passos: Treinamento, validação e teste.
Quais são os tipos gerais de Machine Learning?
Os tipos são, machine learning supervisionado, machine learning não supervisionado, machine Learning semi-supervisionado e aprendizagem por reforço.
Qual a melhor linguagem para Machine Learning?
A melhor linguagem de programação para Machine Learning pode ser cada uma dessas: Python, R, Java, JavaScript e Julia.
Deixe um comentário