
O poder do profissional de Python para Análise de Dados
Um analista de dados usa ferramentas de programação para extrair grandes quantidades de dados complexos, e encontra informações relevantes a partir destes dados. Em suma, um analista é alguém que extrai significado de dados confusos. Um analista que utiliza o Python para análise de dados precisa ter habilidades nas seguintes áreas, a fim de ser valorizado:
Domínio da área
Para poder extrair dados e obter dados relevantes para seu local de trabalho, um analista precisa ter conhecimento do entorno.
Habilidades de Programação
Como analista de dados, você precisará conhecer as bibliotecas certas para usar a fim de limpar os dados, filtrar, e obter resultados a partir deles.
Estatística
Um analista pode precisar usar algumas ferramentas estatísticas para auxiliar na extração dos dados.
Habilidades de visualização de dados com Python
Um analista de dados precisa ter grandes habilidades na visualização de dados, a fim de resumir e apresentar dados a terceiros.
Resultado
Finalmente, um analista precisa comunicar suas descobertas a uma parte interessada ou cliente. Isto significa que eles precisarão reportar o histórico dos dados, e ter a capacidade de narrá-la.
Neste artigo, trago um processo completo da utilização do Python para análise de dados.
Se você seguir este tutorial e codificar tudo como eu fiz, você poderá então usar estes códigos e ferramentas para futuros projetos de análise de dados.
O que veremos neste artigo:
O poder do profissional de Python para análise de dados
Começaremos com o download e a limpeza do conjunto de dados, e depois passaremos à análise e visualização. Finalmente, contaremos uma história em torno de nossas descobertas destes dados.
Estarei usando um conjunto de dados do Kaggle chamado Pima Indian Diabetes Database, que você pode baixar para realizar a análise.
Pré-Requisitos
Para toda esta análise, estarei usando a Jupyter Notebook. Você pode usar qualquer IDE Python que quiser.
Você precisará instalar bibliotecas ao longo do caminho, e eu fornecerei links que o acompanharão no processo de instalação.
A Análise
Depois de baixar o conjunto de dados, você precisará ler o arquivo .csv como um DataFrame em Python. Você pode fazer isso usando a biblioteca Pandas.
Se você não tiver instalado, pode fazê-lo com um simples “pip install pandas” em seu terminal. Se você enfrentar alguma dificuldade com a instalação ou simplesmente quiser saber mais sobre a biblioteca Pandas, confira o nosso artigo sobre a biblioteca aqui e também a documentação da biblioteca Pandas aqui.
Confira também outros exemplos utilizando a Biblioteca Pandas
Ler os Dados
Para ler o quadro de dados em Python, você precisará importar o Pandas primeiro. Depois, você pode ler o arquivo e criar um DataFrame com as seguintes linhas de código:
|
1 2 |
import pandas as pd df = pd.read_csv('diabetes.csv') |
Para verificar o cabeçalho do quadro de dados, execute:
|
1 |
df.head() |
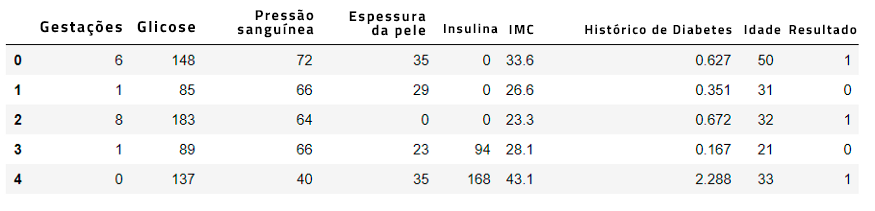
Da imagem acima, você pode ver 9 diferentes colunas com suas respectivas variáveis relacionadas com a saúde de pacientes.
Como analista, você precisará ter uma compreensão básica destas variáveis:
- Gestações: O número de gestações que a paciente teve
- Glicose: O nível de glicose da paciente
- Pressão sanguínea
- Espessura da pele: Espessura da pele da paciente
- Insulina: Nível de insulina da paciente
- IMC: Índice de Massa Corporal da paciente
- Histórico de Diabetes: Histórico do diabetes mellitus em parentes
- Idade
- Resultado: Se a paciente tem ou não diabetes
Variáveis numéricas
São variáveis que possuem uma medida, e têm algum tipo de significado numérico. Todas as variáveis deste conjunto de dados, exceto “resultado”, são numéricas.
Variáveis categóricas
Também são chamadas variáveis nominais, e possuem duas ou mais categorias em que podem ser classificadas.
A variável “resultado” é categórica – onde “0” representa a ausência de diabetes, e “1” representa a presença de diabetes.
Uma breve Nota
Antes de continuar com a análise, gostaria de fazer uma nota rápida:
Os analistas são humanos, e muitas vezes vêm com noções pré-concebidas sobre o que esperamos ver nos dados.
Por exemplo, você esperaria que uma pessoa mais velha tivesse uma probabilidade maior de ter diabetes. Você gostaria de ver esta correlação nos dados, todavia, pode nem sempre ser o caso.
Mantenha uma mente aberta durante o processo de análise e não deixe que seu pré-conceito afete a tomada de decisão.
Especificações do Pandas
Esta é uma ferramenta muito útil que pode ser utilizada pelos analistas. Ela gera um relatório de análise sobre o DataFrame, e ajuda a entender melhor a correlação entre as variáveis.
Para gerar um relatório de especificações Pandas, execute as seguintes linhas de código:
|
1 2 |
import pandas_profiling as pp pp.ProfileReport(df) |
Este relatório lhe dará algumas informações estatísticas gerais sobre o conjunto de dados, que se parece com isto:
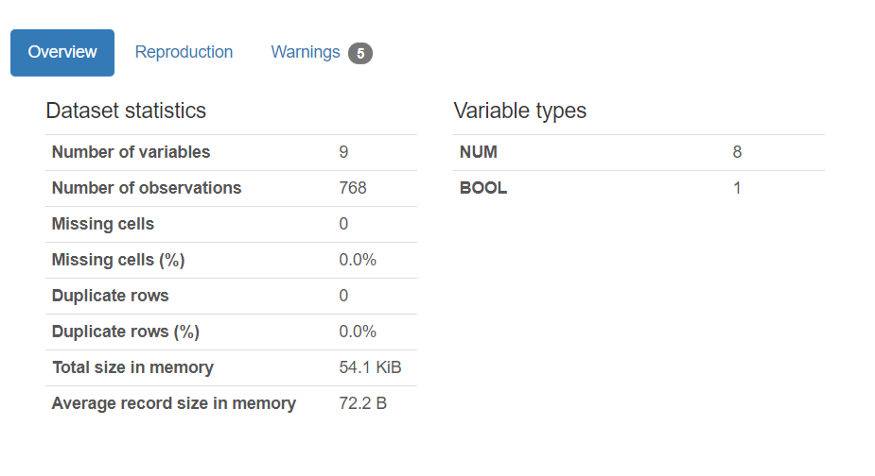
Basta olhar para as dataset do conjunto de dados para ver que não há células ausentes ou duplicadas em nosso DataFrame.
As informações fornecidas acima geralmente exigem que corramos algumas linhas de códigos para encontrar o que desejamos, mas são geradas muito mais facilmente com o Pandas.
O Pandas também fornece mais informações sobre cada variável. Vou mostrar um exemplo:
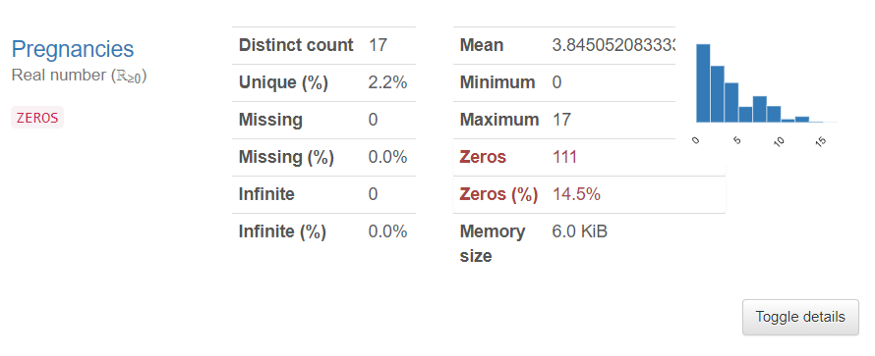
Esta é a informação gerada para a variável chamada “Gestações”.
Como analista, este relatório economiza muito tempo, pois não temos que passar por cada variável individual e executar muitas linhas de código.
A partir daqui, podemos ver isso:
- A variável “Gestações” tem 17 valores distintos.
- O menor número na coluna gestações é “0”, e o maior é “8”.
- O número de valores “zero” nesta coluna é bastante baixo (apenas 14,5%). Isto significa que acima de 80% das pacientes do dataset estão grávidas.
No relatório, há informações como estas fornecidas para cada variável. Isto nos ajuda muito em nosso entendimento do dataset e de todas as colunas nele contidas.
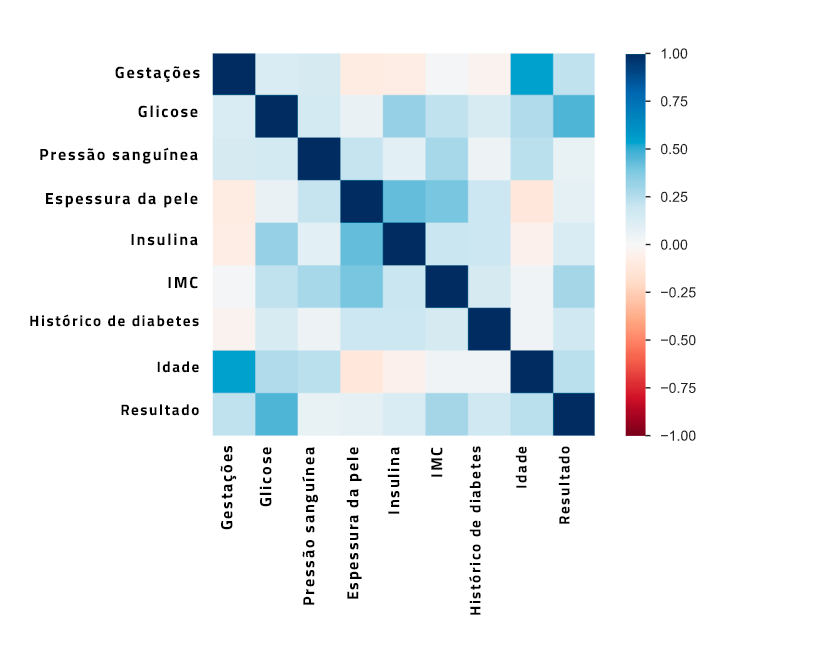
A imagem acima é uma matriz de correlação. Ela nos ajuda a compreender melhor a correlação entre as variáveis do dataset.
Há uma leve correlação negativa entre as variáveis “Idade” e “Espessura da pele”, que pode ser examinada mais a fundo na seção de visualização da análise.
Como não há linhas faltantes ou duplicatas no dataset como visto acima, não precisamos fazer nenhuma limpeza ou adequação adicional de dados.
Visualização dos dados
Agora que temos uma compreensão básica de cada variável, podemos tentar encontrar a relação entre elas utilizando o python para análise de dados.
A maneira mais simples e rápida de fazer isso é gerando visualizações.
Neste tutorial, utilizaremos três bibliotecas para realizar o trabalho – Matplotlib, Seaborn, e Plotly.
Se você é iniciante em Python, sugiro começar e se familiarizar com Matplotlib e Seaborn.
Aqui está a documentação para a Matplotlib, e aqui a da Seaborn. Eu sugiro fortemente que você passe algum tempo lendo a documentação e fazendo os tutoriais usando estas duas bibliotecas a fim de melhorar suas habilidades de visualização.
Plotly é uma biblioteca que permite criar gráficos interativos, e requer um pouco mais de familiaridade com Python para dominar. Você pode encontrar o guia de instalação e os requisitos aqui.
Se você seguir exatamente este tutorial, você será capaz de fazer belos gráficos com estas três bibliotecas. Você poderá então usar meu código como modelo para qualquer tarefa futura de análise ou visualização no futuro.
Visualização da variável de resultado
Primeiro, execute as seguintes linhas de código para importar Matplotlib, Seaborn, Numpy, e Plotly após a instalação:
|
1 2 3 4 5 6 7 8 9 10 |
# Visualization Importsimport matplotlib.pyplot as plt import seaborn as sns color = sns.color_palette() get_ipython().run_line_magic('matplotlib', 'inline') import plotly.offline as py py.init_notebook_mode(connected=True) import plotly.graph_objs as go import plotly.tools as tls import plotly.express as px import numpy as np |
Em seguida, execute as seguintes linhas de código para criar um gráfico visualizando a variável Resultado:
|
1 2 3 4 5 6 7 8 |
dist = df['Resultado'].value_counts() colors = ['mediumturquoise', 'darkorange'] trace = go.Pie(values=(np.array(dist)),labels=dist.index) layout = go.Layout(title='Resultado da Diabetes') data = [trace] fig = go.Figure(trace,layout) fig.update_traces(marker=dict(colors=colors, line=dict(color='#000000', width=2))) fig.show() |
Isto é feito com a biblioteca Plotly, e você terá um gráfico interativo que se parece com este:
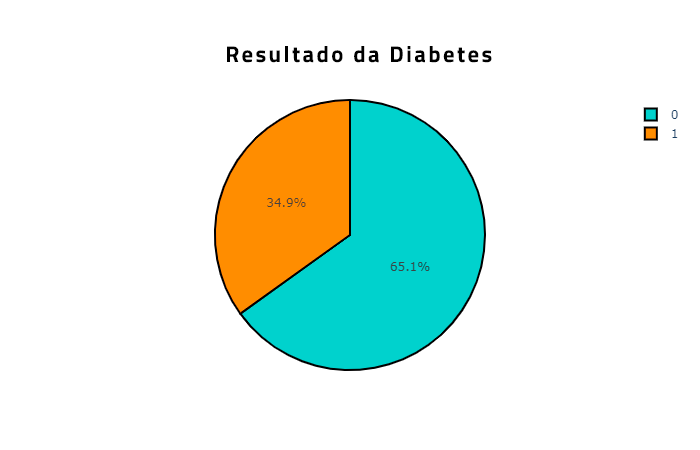
Você pode brincar com a tabela e escolher mudar as cores, rótulos e legendas.
No entanto, pelo quadro acima, podemos ver que a maioria dos pacientes no dataset não são diabéticos. Menos da metade deles têm como resultado , o “1” (têm diabetes).
Matriz de correlação com Plotly
Similar à matriz de correlação gerada em Pandas, podemos criar uma usando Plotly:
|
1 2 3 4 5 6 7 |
def df_to_plotly(df): return {'z': df.values.tolist(), 'x': df.columns.tolist(), 'y': df.index.tolist() }import plotly.graph_objects as go dfNew = df.corr() fig = go.Figure(data=go.Heatmap(df_to_plotly(dfNew))) fig.show() |
Os códigos acima irão gerar uma matriz de correlação que é similar à acima:
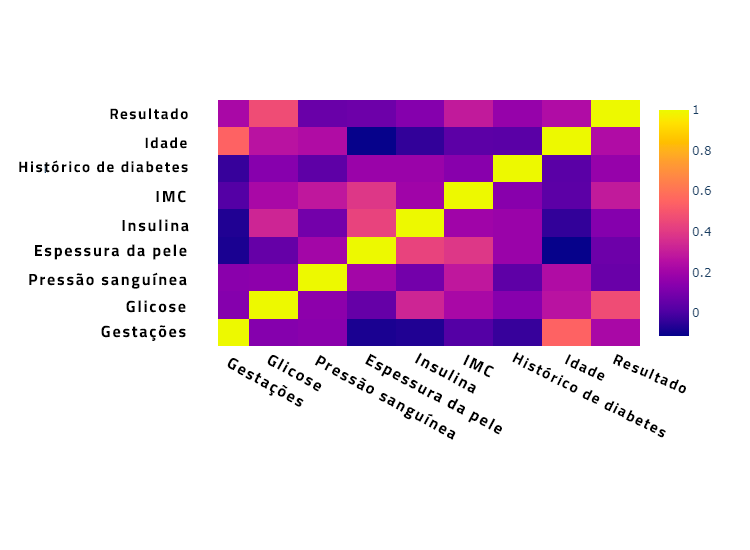
Novamente, semelhante à matriz gerada acima, uma correlação positiva pode ser observada entre as variáveis
- Idade e Gravidez
- Glicose e Resultado
- Espessura da Pele e Insulina
Visualização dos níveis de glicose e insulina
|
1 2 3 4 5 |
fig = px.scatter(df, x='Glicose', y='Insulina') fig.update_traces(marker_color="turquoise",marker_line_color='rgb(8,48,107)', marker_line_width=1.5) fig.update_layout(title_text='Glicose e Insulina') fig.show() |
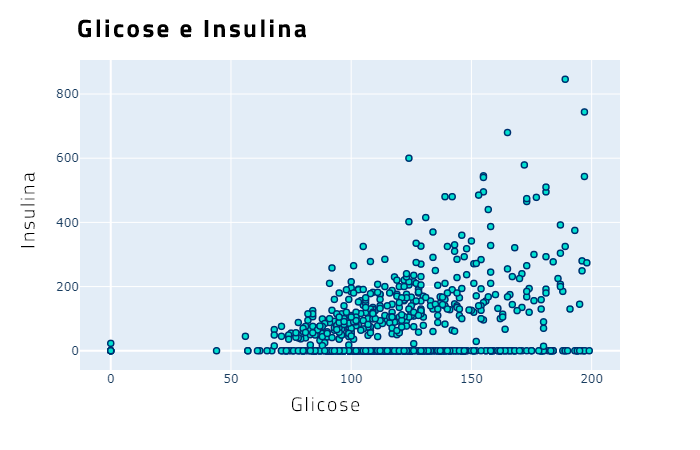
Há uma correlação positiva entre as variáveis glicose e insulina. Isto faz sentido, porque para uma pessoa com níveis mais altos de glicose, seria esperado que a mesma utilizasse mais insulina.
Visualizar os resultados e a idade com o Python para análise de dados
Agora, vamos visualizar o resultado e a idade das variáveis. Para isso, criaremos um boxplot, usando o código abaixo:
|
1 2 3 4 5 |
fig = px.box(df, x='Resultado', y='Idade') fig.update_traces(marker_color="midnightblue",marker_line_color='rgb(8,48,107)', marker_line_width=1.5) fig.update_layout(title_text='Idade e Resultado') fig.show() |
O resultado do plot será um pouco parecida com isto:
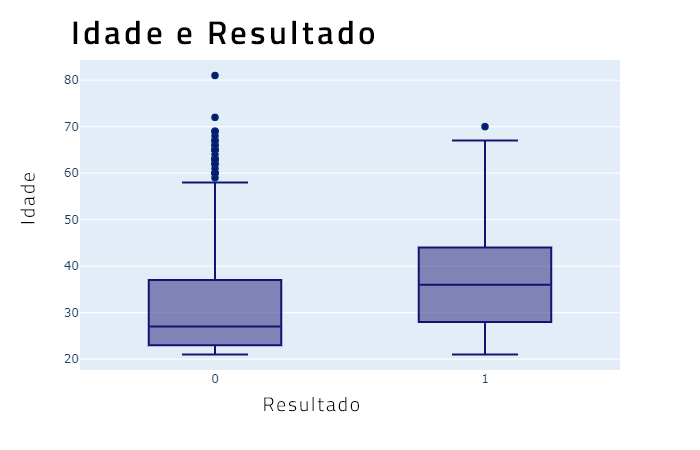
Pelo plot acima, você pode ver que as pessoas mais velhas são mais propensas a ter diabetes. A idade média para adultos com diabetes é de cerca de 35 anos, enquanto que para pessoas sem diabetes é muito mais baixa.
No entanto, há muitos valores atípicos.
Há alguns idosos sem diabetes (um mesmo com mais de 80 anos), que podem ser observados no boxplot.
Visualização do IMC e dos resultados
Finalmente, vamos visualizar as variáveis “IMC” e “Resultado”, para ver se existe alguma correlação entre as duas variáveis.
Para fazer isso, utilizaremos a biblioteca Seaborn:
|
1 |
plot = sns.boxplot(x='Resultado',y="IMC",data=df) |
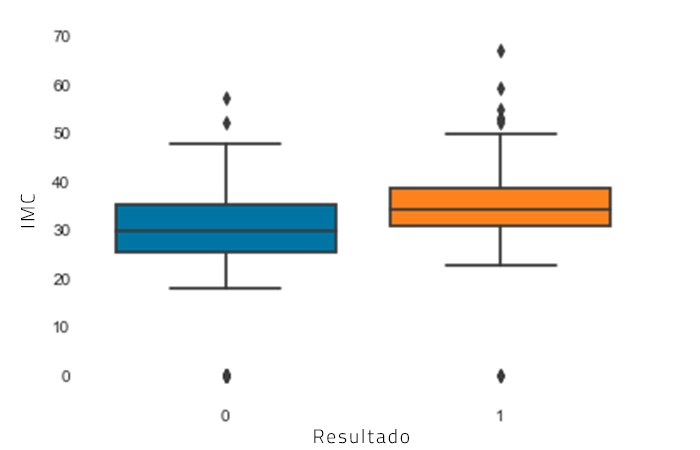
O boxplot criado aqui é semelhante ao criado acima usando o Plotly. Entretanto, o Plotly é melhor na criação de visualizações que são interativas, e os gráficos parecem mais bonitos comparados com os feitos em Seaborn.
Pelo gráfico da caixa acima, podemos ver que um IMC mais elevado se correlaciona com um resultado positivo. Pessoas com diabetes tendem a ter IMC mais altos do que pessoas sem diabetes.
Você pode fazer mais visualizações como as acima, simplesmente mudando os nomes das variáveis e executando as mesmas linhas de código.
Vou deixar isso como um exercício para você fazer, para ter uma melhor compreensão de suas habilidades com o Python para análise de dados.
Retorno de dados
Finalmente, podemos contar uma história em torno dos dados que analisamos e visualizamos. Nossas descobertas podem ser discriminadas da seguinte forma:
As pessoas com diabetes são altamente propensas a serem mais velhas do que as que não têm. Elas também têm maior probabilidade de ter IMC mais alto, ou de sofrer de obesidade. Também é mais provável que tenham níveis mais altos de glicose em seu sangue. Pessoas com níveis mais altos de glicose também tendem a tomar mais insulina, e esta correlação positiva indica que pacientes com diabetes também poderiam ter níveis mais altos de insulina (esta correlação pode ser verificada através da criação de um gráfico de dispersão).
O que aprendemos com este artigo?
O que um bom profissional de Python para análise de dados precisa ter?
O bom profissional precisa ter o domínio da área analisada, habilidades de programação, estatística, habilidade de visualização de dados e storytteling.
Quais são os pré-requisitos para realizar uma boa análise de dados com o Python?
Ter instalado uma IDE Python e também bibliotecas diversas de visualização de dados.
Qual a principal característica que um profissional precisa para analisar bem um dado?
Manter uma mente aberta durante o processo de análise não deixando que seu pré-conceito afete a tomada de decisão.
Quais são as principais bibliotecas para visualização de dados com Python?
Biblioteca Pandas, Matplotlib, Seaborn e Plotly.
Como fazer um bom storytelling para a visualização de dados?
É preciso saber resumir e concatenar os dados obtidos para contar uma história sucinta e relevante de acordo com as descobertas obtidas.
Isso é tudo por este artigo! Espero que você tenha achado este tutorial útil e possa usá-lo como uma referência futura para projetos que você venha a criar. Boa sorte em sua jornada com o python para análise de dados, e feliz aprendizado!
Artigo inspirado e adaptado de:
https://towardsdatascience.com/a-beginners-guide-to-data-analysis-in-python-188706df5447
Deixe um comentário