Aluno: Carlos Eduardo Lopes
Formação em Cientista de Dados
Resumo
A proposta de trabalho final para conclusão da formação em cientista de dados é trabalhar com um tema que me identifico muito e criar um modelo preditivo com o Python, e realizar a previsão para os próximos períodos e visualizá-lo através de ferramentas de Business Inteligence.
Objetivo
Desenvolver modelos preditivos analisando várias hipóteses de modelos escolhendo aquele com melhor desempenho para utilização dentro do BI.
Execução do projeto
Para esse projeto inicialmente foi realizada uma busca na base de dados da www.kaggle.com, a intensão deste projeto desde o início era realizar um modelo preditivo de vendas. Encontrada uma base de dados de uma empresa de varejo foi possível iniciar o processo de modelagem. (https://www.kaggle.com/tevecsystems/retail-sales-forecasting)
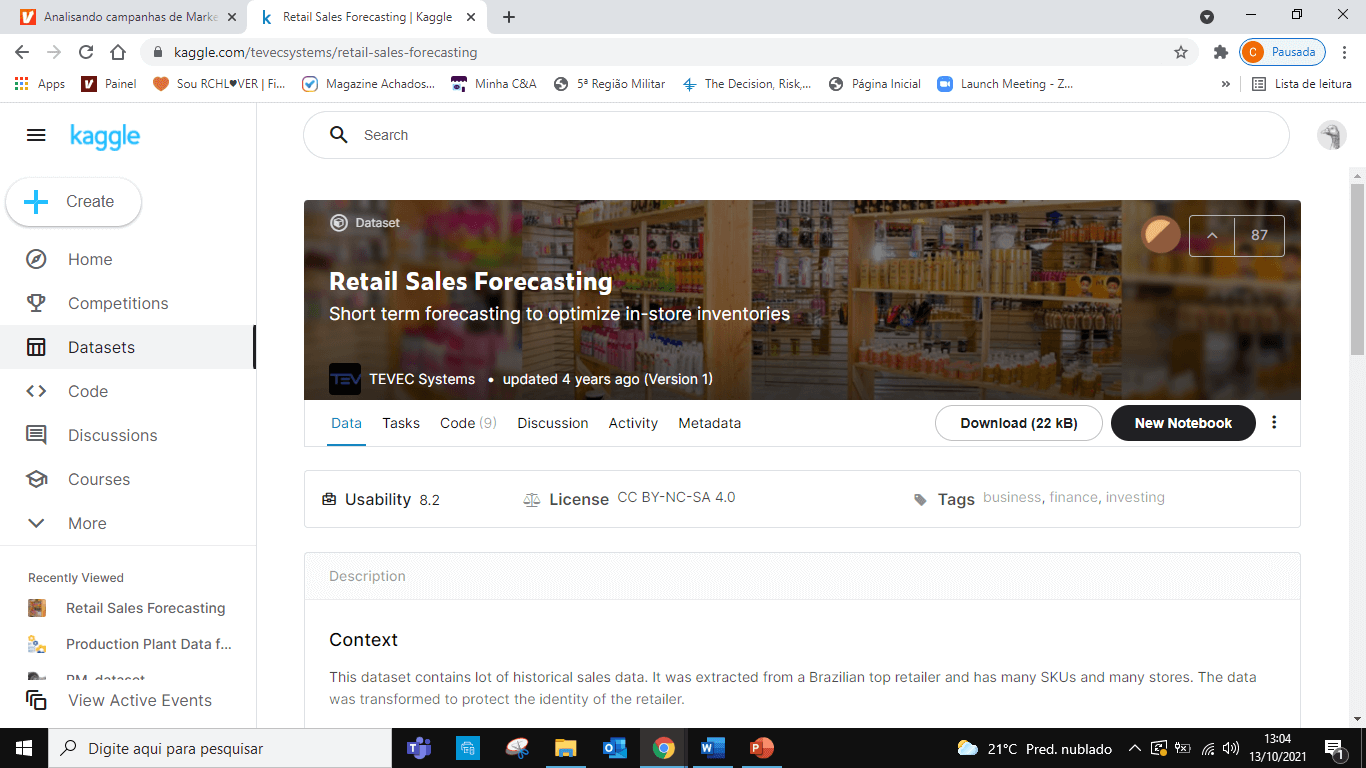
Salvo os dados na plataforma GitHub foi identificada que a base de dados possuía os seguintes parâmetros: data da venda, preço, volume de estoque do dia e volume de vendas.

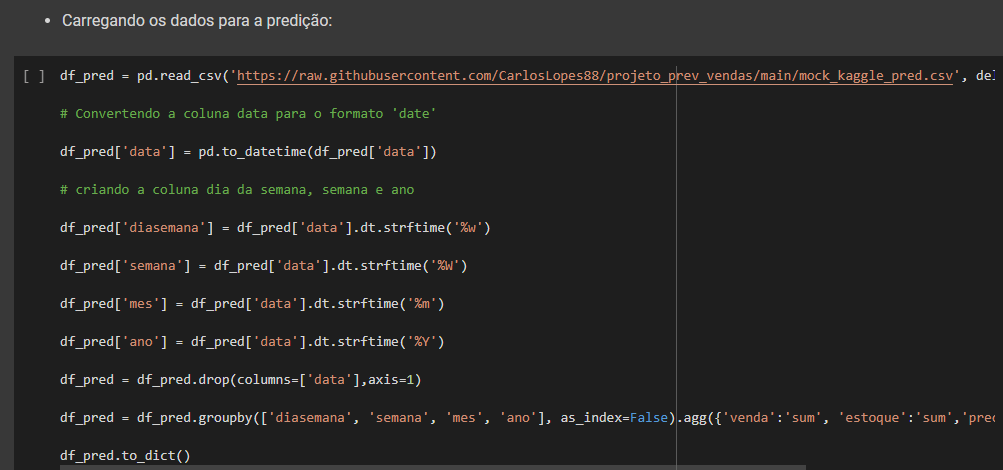
Após essa análise inicial processo iniciou-se o processo de ETL. A base de dados foi carregada através da biblioteca pandas, para a modelagem foi realizado os seguintes ajustes, conversão do campo ‘data’ que estava como objeto para data, e retirada os campos que era string para o treinamento do modelo, e acrescentada variáveis retiradas da data como semana, dia da semana, mês e ano.
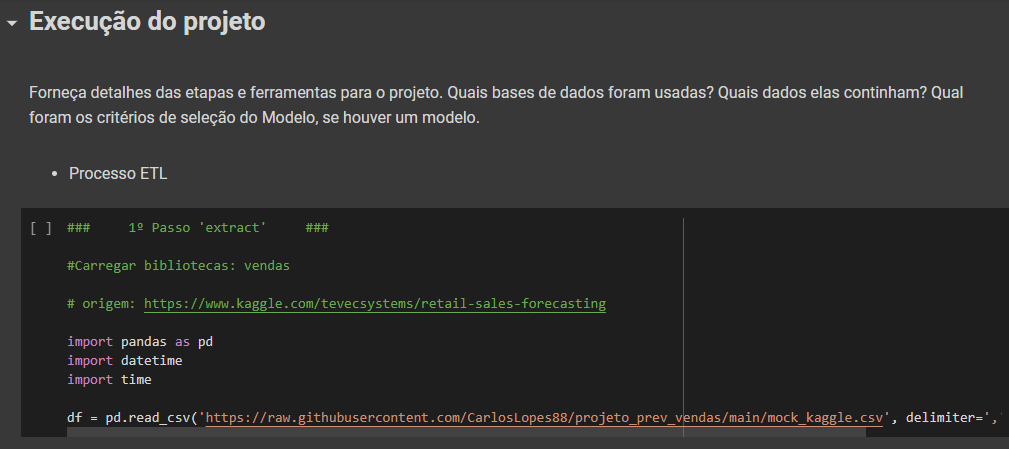
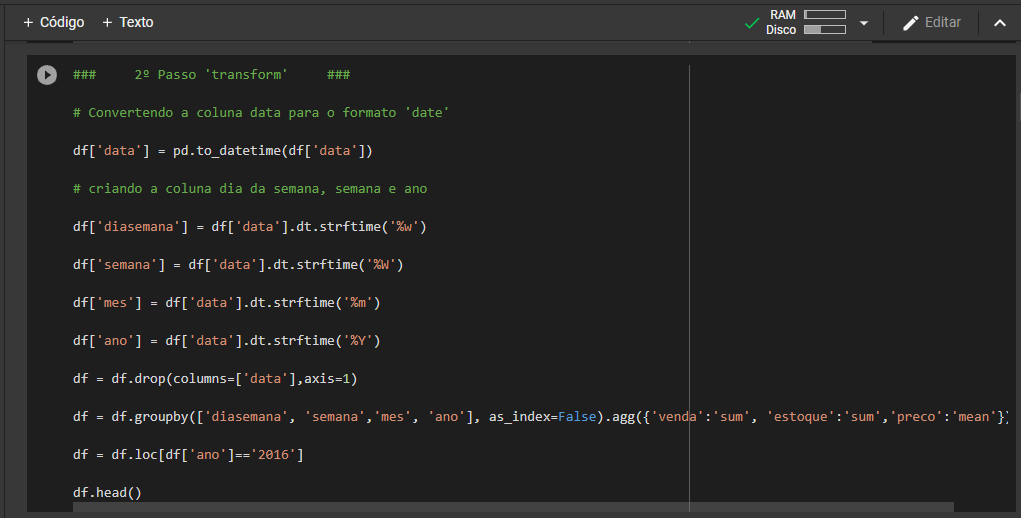
Após todo o tratamento foi realizada uma análise exploratória dos dados para identificarmos possíveis pontos que pudessem trazer insights para o modelo.
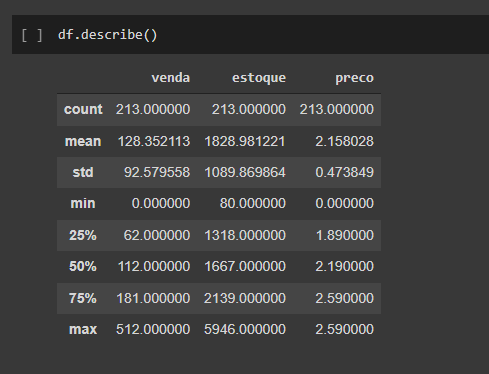
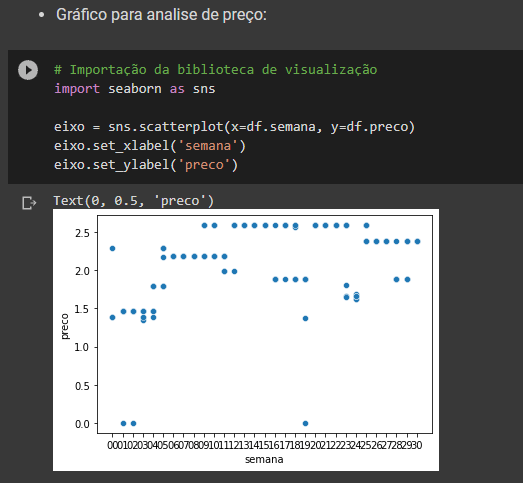
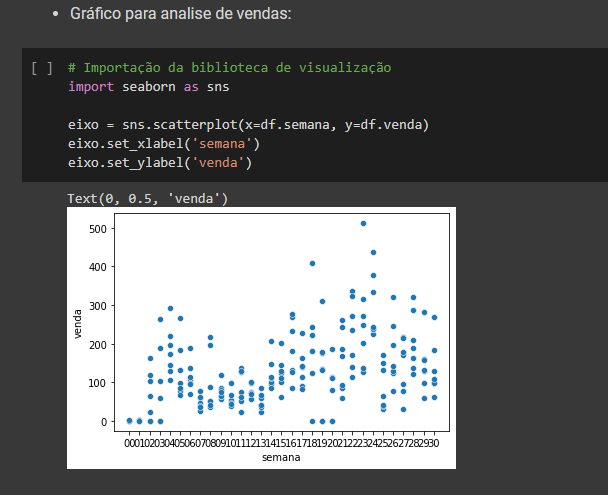
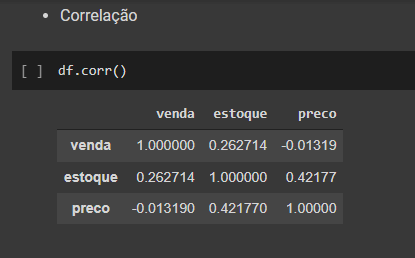
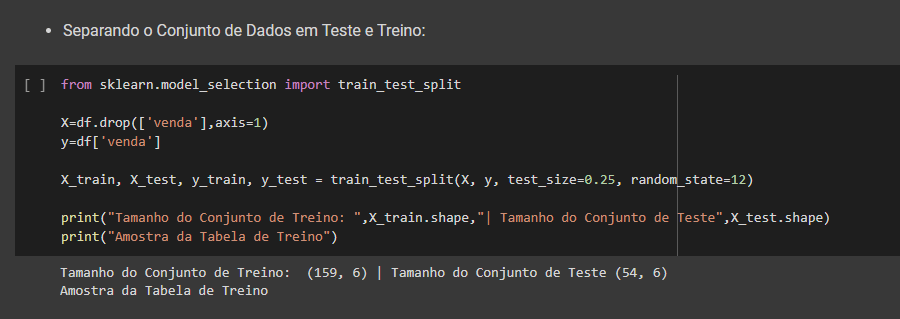
Com a biblioteca scikit-learn foi separado os dados entre treino e teste para realizarmos a execução dos modelos preditivos e testes dos mesmos para avaliarmos sua performance.
Ainda usando a biblioteca citada realizamos cinco análises com os dados, através de regressão linear, regressão não linear (polinomial de grau 2), arvore de decisão de regressão, Random forest regression e redes neurais MPL. Após avaliar os 5 modelos vimos que nenhum deles obteve score satisfatório para resolver o problema.
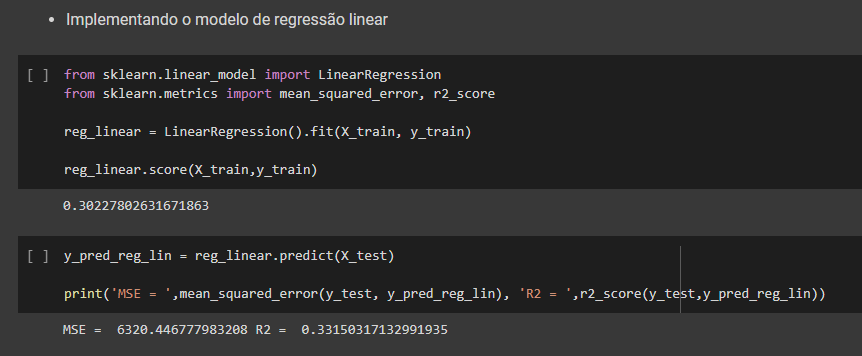
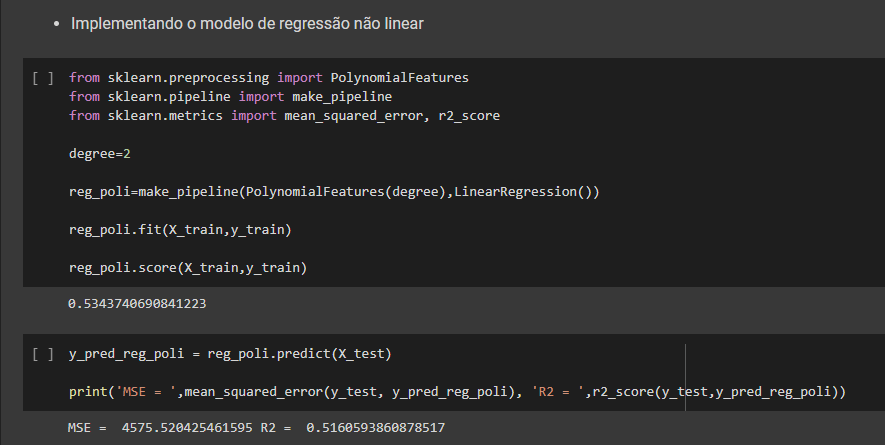
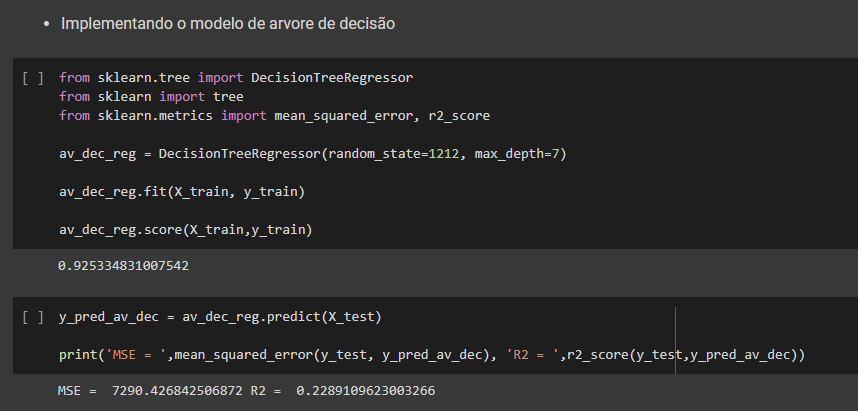
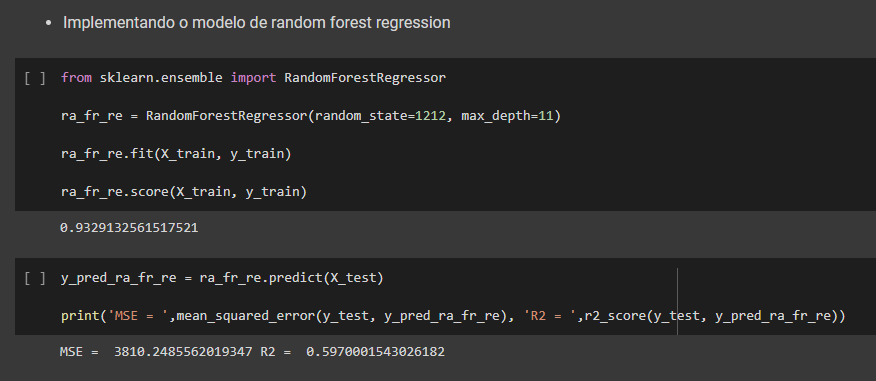
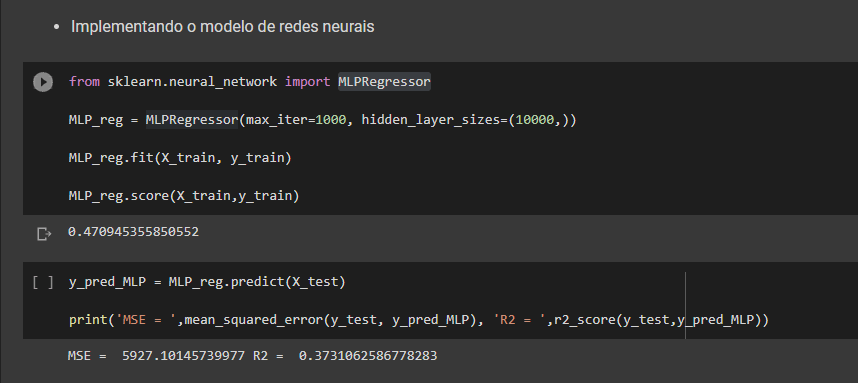
Mesmo com o resultado não satisfatórios para fins didáticos, após esse processo foi carregado um data frame com duas semana simulando os parâmetros para previsão de duas semana. Com esses dados foi consolidado os dados históricos com os dados da previsão e exportado em csv finalizando o processo de ETL.

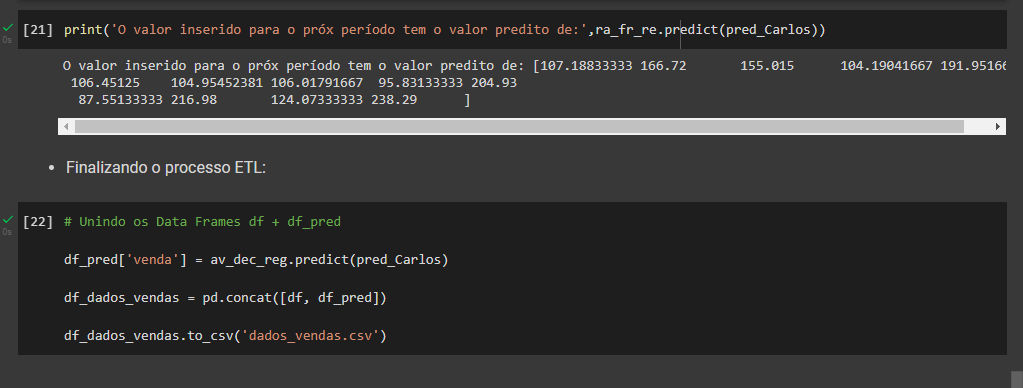
Essa nova base de dados alimentou um dashboard criado no power bi finalizando o projeto gerando a visualização desses dados.

Conclusões
Com os dados foi possível realizar todo o processo para os modelos preditivos e criticá-los para a entrega final. Creio que em um processo no dia a dia seria interessante agregar novas variáveis para deixar o modelo melhor como por exemplo desconto, quantidade de itens promocionados, datas comemorativas como black friday, agregariam ao processo. Testar também o dataset em outros modelos como os de series temporais.
Ao final carregar os dados diretamente em um banco de dados SQL deixariam o processo mais robusto.
O que é possível enxergar com a experiência acima que os modelos preditivos tem comportamentos diferentes para cada tipo de dado, e para uma melhor performance o ideal é testar vários modelos e modelar seus dados de forma diferente (feature engineering) para encontrar um ponto de equilíbrio em performance e acuracidade do modelo.
Referências e Notebooks.
Notebook do Projeto, disponível em
Base de dados utilizada disponível
https://www.kaggle.com/tevecsystems/retail-sales-forecasting
O que aprendemos neste artigo:
Qual a linguagem utilizada nesse projeto final?
A proposta de trabalho final para conclusão da formação em cientista de dados é trabalhar com um tema que me identifico muito e criar um modelo preditivo com o Python.
Qual a base de dados utilizada na analise?
Base de dados de uma empresa de varejo
O que significa a sigla BI?
Business Inteligence
Qual são as bibliotecas utilizadas nesse processo?
Pandas, Scikit Learn e Seaborn
Deixe um comentário