Formação Prática Presencial
Cientista de
Dados
Formação Prática Presencial
Cientista de
Dados
Seja referência na carreira com a Ciência de Dados.
Curso Data Science Curitiba
Início em: carregando data... Duração: 4 meses
Metodologia prática validada Alto índice de satisfação Aceleração do aprendizado






Para quem é o Curso Data Science Curitiba da Harve
Para quem é o Curso Data Science Curitiba da Harve
Para quem busca uma
nova carreira
- Sobram vagas e faltam profissionais qualificados na ciência de dados
- Salários atrativos e com altos benefícios
- Preparação intensiva para o mercado de trabalho
- Aprenda de forma acelerada com uma metodologia prática e validada
Para quem busca uma
nova habilidade
- Possibilidade de crescimento rápido com as habilidades em Data Science
- Melhora a sua entrega e produtividade
- Mais profissionalismo para gerar novas hipóteses baseadas em dados
- Aplicabilidade imediata nos seus desafios atuais
 “A Harve se propõe a ensinar, desde iniciantes até pessoas mais avançadas, mesclando diversas áreas de atuação. A mesma experiência de networking que se encontra em um MBA, também é vivenciado na Harve, uma vez que temos uma galera formada de diversos setores.”
“A Harve se propõe a ensinar, desde iniciantes até pessoas mais avançadas, mesclando diversas áreas de atuação. A mesma experiência de networking que se encontra em um MBA, também é vivenciado na Harve, uma vez que temos uma galera formada de diversos setores.”
Lucas Roberto Sawa – Aluno Harver
 “Ao longo desses meses obtive muito conhecimento por meio da teoria e prática em diversos assuntos, desde os fundamentos de análise de dados até tópicos mais avançados como IA e Machine Learning. O curso fortaleceu demais as minhas bases nesse universo de Ciência de Dados e me fez ter ainda mais convicção de que estou trilhando o caminho certo na minha carreira. “
“Ao longo desses meses obtive muito conhecimento por meio da teoria e prática em diversos assuntos, desde os fundamentos de análise de dados até tópicos mais avançados como IA e Machine Learning. O curso fortaleceu demais as minhas bases nesse universo de Ciência de Dados e me fez ter ainda mais convicção de que estou trilhando o caminho certo na minha carreira. “
Andrew Rodrigues de Oliveira – Aluno Harver
 “Acertei em cheio, conheci mentores incríveis com grande conhecimento, experiência e principalmente a didática para orientar os que estavam iniciando sua caminhada nesse mundo novo.”
“Acertei em cheio, conheci mentores incríveis com grande conhecimento, experiência e principalmente a didática para orientar os que estavam iniciando sua caminhada nesse mundo novo.”
Brian Kooji – Aluno Harver
 “Escolhi o curso que oferecesse a melhor ementa para o que eu esperava aperfeiçoar. Sinto que nesse sentido a Harve seja a melhor instituição no momento.”
“Escolhi o curso que oferecesse a melhor ementa para o que eu esperava aperfeiçoar. Sinto que nesse sentido a Harve seja a melhor instituição no momento.”
Brendha Lima – Aluna Harver
 “Senti que o curso agregou bastante dando uma base sólida para aprofundar meus estudos. Com certeza usarei muito no dia a dia. O objetivo agora é continuar no dessa nova skill.”
“Senti que o curso agregou bastante dando uma base sólida para aprofundar meus estudos. Com certeza usarei muito no dia a dia. O objetivo agora é continuar no dessa nova skill.”
Conrado Teixeira – Aluno Harver
 “Excelente curso, boa didática, facilitadores comprometidos e muito gentis. Tornou o que parecia impossível em agradável e compreensível.”
“Excelente curso, boa didática, facilitadores comprometidos e muito gentis. Tornou o que parecia impossível em agradável e compreensível.”
Isabelly Wojcik – Aluna Harver
Quais conhecimentos preciso para fazer o Curso Data Science Curitiba da Harve?
Quais conhecimentos preciso para fazer o Curso Data Science Curitiba da Harve?
Não é preciso saber programar
Na formação você irá desenvolver esta competência. Basta gostar de resolver problemas e ter visão analítica.
Ser curioso para explorar
Você irá conseguir encontrar as soluções de maneira muito mais simples e rápida com esta competência.

Gostar de trabalhar com raciocínio lógico
Você irá tratar e manipular dados lógicos que irão ajudar em tomadas de decisões do seu projeto
Vontade de aprender
Ter a sede de conhecimento é o principal requisito para você ter sucesso no aprendizado
Ementa do Curso Data Science Curitiba
Ementa do Curso Data Science Curitiba
Apresentação Inicial (Clique para expandir)
Objetivo: Apresentar a Harve e funcionamento das plataformas de ensino e funcionamento da formação, mentorias e outros benefícios da Escola.
- Conceito de Andragogia
- O que é CSAT e sua aplicação na Harve
- Funcionamento e ferramentas do Workplace
- Harve além da sala de Aula
- Apresentação dos Alunos
SQL (Clique para expandir)
Objetivo: Compreender a sintaxe SQL e ser capaz de aplicar consultas em bases de dados.
- ACESSANDO UMA BASE DE DADOS
- TIPOS DE DADOS
- OPERADORES ARITMÉTICOS
- FUNÇÕES MATEMÁTICAS
- WHERE
- BOOTCAMP
- OPERADORES AND, OR E NOT
- AS
- IS
- DISTINCT
- ORDER BY
- FUNÇÕES DE AGREGAÇÃO
- CASE SENSITIVE E LIKE
- INNER JOIN
- LEFT e RIGHT JOIN
- UNION
- FORMAT
- CONCAT , CAST e REPLACE
- GROUP BY
Introdução ao Python (Clique para expandir)
Objetivo: Compreender os conceitos de lógica de programação e a sintáxe da linguagem Python, aplicando em um exercício.
- INSTALANDO O PYTHON
- ESCOLHENDO UMA IDE
- IMPRIMINDO
- CONCEITO DE VARIÁVEL
- OPERADORES MATEMÁTICOS
- CAST
- BOOTCAMP
- IF
- IF ELSE
- AND,OR E NOT
- BOOTCAMP
- LISTA
- FOR
- WHILE
- BOOTCAMP
- FUNÇÕES CRIANDO
- DICIONÁRIOS
- BOOTCAMP
Exploração de Dados (Clique para expandir)
Objetivo: Aplicar técnicas de estatística descritiva em dados.
- TIPOS DE DADOS
- MEDIDAS DE POSIÇÃO
- MEDIDAS SEPARATRIZES
- MEDIDAS DE DISPERÇÃO
- DISTRIBUIÇÃO DE FREQUÊNCIA
- TABELA DE CONTINGÊNCIA
- GRÁFICO DE DISPERSÃO
- CORRELAÇÃO DE PEARSON
- REGRESSÃO LINEAR
- GERANDO EXPRESSÃO LINEAR
- TESTE A/B
- TESTE A/B AMOSTRAGEM
- BOOTCAMP
Python Pandas (Clique para expandir)
Objetivo: Manipular as funções da biblioteca pandas do Pythton, compreendo as suas funcionalidades.
- INSTALAÇÃO E IMPORTAÇÃO DA BIBLIOTECA
- CRIANDO AS PRIMEIRAS ESTRUTURAS
- IMPORTANDO DADOS
- INSERINDO ITEM COM APPEND
- INSPEÇÃO DE CONJUNTO
- INSPEÇÃO DE COLUNA
- INSPEÇÃO DE CONTEÚDO
- BOOTCAMP
- ATRIBUIÇÃO DE DADOS
- FILTROS
- FILTROS UTILIZANDO AND E OR
- DADOS FALTANTES E DUPLICADOS
- BOOTCAMP
- RESUMO ESTATÍSTICO
- AGRUPAMENTO
- VISUALIZAÇÃO DE DADOS
- CONECTANDO DADOS
- SALVANDO DADOS
- BOOTCAMP
Python ETL (Clique para expandir)
Objetivo: Aplicar de forma assertiva a funcionalidade ETL, no formato CSV, banco de dados e API na programação com Python.
- CONHECENDO NOSSO ARQUIVO
- CRIANDO COLUNAS
- CATEGORIZAÇÃO DE DADOS
- TRATANDO VALORES NULOS
- BOOTCAMP
- APAGANDO COLUNAS
- PORQUÊ USAR APIS
- MONTANDO URL
- EXECUTANDO ENVIO APIS
- TRANSFORMANDO DATA
- IDENTIFICANDO COLUNAS
- TRATANDO CONTEÚDOS DATAFRAME
- BOOTCAMP
- EXPORTANDO PARA CSV
- CREDENCIAIS PARA BANCO DE DADOS
- ESCREVENDO EM UM BANCO DE DADOS
- LENDO DADOS EM UM BANCO DE DADOS
- BOOTCAMP
Visualização de Dados (Clique para expandir)
Objetivo: Criar dashboards na ferramenta power bi, conseguindo aplicar técnicas durante todo o ciclo do dado, desde a sua captura dentro da ferramenta até a visualização.
- PASSOS PARA UMA VISUALIZAÇÃO EFICIENTE
- INICIANDO COM POWER BI
- CONECTANDO DADOS
- MÉTRICAS E DIMENSÕES
- GRÁFICO DE BARRA
- FILTROS DE DADOS
- GRÁFICO DE LINHA E SÉRIE TEMPORAL
- GRÁFICO DE PIZZA
- ADICIONANDO CAMPO
- DAX
- CONTROLES DE FILTROS
- GRÁFICO DE DISPERSÃO
- GRÁFICO DE TABELA E TABELA DINÂMICA
- TEXTOS
- RELACIONAMENTO ENTRE DADOS
- GRÁFICO DE MAPA
- OUTROS GRÁFICOS
- DESIGN
- BOOTCAMP
IA e Machine Learning (Clique para expandir)
Objetivo: Compreeder conceitos dos principais modelos e aplicá-los em Python conforme problema estabelecido.
- SUBGRUPOS DA INTELIGÊNCIA ARTIFICIAL
- MACHINE LEARNING
- TIPOS DE APRENDIZAGENS
- FLUXO DE UM PROJETO DE MACHINE LEARNING
- MÉTRICAS DE AVALIAÇÃO
- PRINCIPAIS DESAFIOS
- MODELOS DE CLASSIFICAÇÃO
- NAIVE BAYES
- REGRESSÃO LOGÍSTICA
- K-NN
- HIPEPARÂMETROS
- SVM
- ÁRVORES DE DECISÃO
- RANDON FOREST
- REDES NEURAIS
- MODELOS DE REGRESSÃO
- REGRESSÃO LINEAR
- REGRESSÃO POLINOMIAL
- OUTROS MÉTODOS
- AGRUPAMENTO
- K-MEANS
IA Generativa e Engenharia de Prompts
Objetivo: Compreeder os fundamentos, funcionamento, arquitetura e aplicações práticas de modelos generativos de IA.
- EVOLUÇÃO DA IA GENERATIVA (GPT, BERT, LLAMA, ETC.)
- DIFERENÇAS ENTRE MODELOS DE LINGUAGEM (MLM VS. AR)
- COMO OS TRANSFORMERS FUNCIONAM (ATENÇÃO, EMBEDDINGS, TOKENIZAÇÃO)
- DIFERENÇA ENTRE MODELOS PRÉ-TREINADOS E FINE-TUNED
- TIPOS DE PROMPTS: ZERO-SHOT, FEW-SHOT E CHAIN-OF-THOUGHT
- ESTRUTURAÇÃO DE PROMPTS EFICAZES (CLAREZA, CONTEXTO E INTENÇÃO)
- TESTANDO PROMPTS NO OPENAI PLAYGROUND OU API DO LLAMA
- COMPARAÇÃO DE RESPOSTAS COM DIFERENTES ESTRATÉGIAS DE PROMPTING
- USO DE IA PARA GERAR CÓDIGO SQL E PYTHON (EXEMPLOS PRÁTICOS)
- EXTRAÇÃO DE INSIGHTS AUTOMÁTICOS DE BASES DE DADOS
- COMO MODELOS GENERATIVOS PODEM CRIAR DADOS DE TREINO REALISTAS
- FERRAMENTAS COMO FAKER E GPT PARA GERAÇÃO DE DATASETS
- AUTOMATIZANDO LIMPEZA DE DADOS E DETECÇÃO DE PADRÕES
- USO DE IA PARA GERAÇÃO DE RESUMOS E EXPLICAÇÕES DE DADOS
- CRIANDO UM CHATBOT QUE INTERPRETA CONSULTAS SQL
- APLICANDO IA PARA DOCUMENTAÇÃO AUTOMATIZADA DE CÓDIGO
- O QUE É RAG E COMO ELE MELHORA A PRECISÃO DOS MODELOS
- COMPARAÇÃO ENTRE FINE-TUNING VS. RAG
- INTEGRAÇÃO DE RAG COM SQL (EXEMPLO DE BUSCA EM BANCOS DE DADOS)
- HANDS-ON FINAL: CONSTRUINDO UM PIPELINE COM IA GENERATIVA + RAG
Imersão de carreira Harve (Clique para expandir)
Objetivo: Neste módulo, você vai vivenciar o dia a dia de um cientista de dados através de projetos reais. Uma oportunidade de unir todo o conhecimento e práticas feitas durante a formação para uma verdadeira imersão no mercado de trabalho digital.
Apresentação Inicial
Objetivo: Apresentar a Harve e funcionamento das plataformas de ensino e funcionamento da formação, mentorias e outros benefícios da Escola.
- Conceito de Andragogia
- O que é CSAT e sua aplicação na Harve
- Funcionamento e ferramentas do Workplace
- Harve além da sala de Aula
- Apresentação dos Alunos
SQL
Objetivo: Compreender a sintaxe SQL e ser capaz de aplicar consultas em bases de dados.
- ACESSANDO UMA BASE DE DADOS
- TIPOS DE DADOS
- OPERADORES ARITMÉTICOS
- FUNÇÕES MATEMÁTICAS
- WHERE
- BOOTCAMP
- OPERADORES AND, OR E NOT
- AS
- IS
- DISTINCT
- ORDER BY
- FUNÇÕES DE AGREGAÇÃO
- CASE SENSITIVE E LIKE
- INNER JOIN
- LEFT e RIGHT JOIN
- UNION
- FORMAT
- CONCAT , CAST e REPLACE
- GROUP BY
Introdução ao Python
Objetivo: Compreender os conceitos de lógica de programação e a sintáxe da linguagem Python, aplicando em um exercício.
- INSTALANDO O PYTHON
- ESCOLHENDO UMA IDE
- IMPRIMINDO
- CONCEITO DE VARIÁVEL
- OPERADORES MATEMÁTICOS
- CAST
- BOOTCAMP
- IF
- IF ELSE
- AND,OR E NOT
- BOOTCAMP
- LISTA
- FOR
- WHILE
- BOOTCAMP
- FUNÇÕES CRIANDO
- DICIONÁRIOS
- BOOTCAMP
Exploração de Dados
Objetivo: Aplicar técnicas de estatística descritiva em dados.
- TIPOS DE DADOS
- MEDIDAS DE POSIÇÃO
- MEDIDAS SEPARATRIZES
- MEDIDAS DE DISPERÇÃO
- DISTRIBUIÇÃO DE FREQUÊNCIA
- TABELA DE CONTINGÊNCIA
- GRÁFICO DE DISPERSÃO
- CORRELAÇÃO DE PEARSON
- REGRESSÃO LINEAR
- GERANDO EXPRESSÃO LINEAR
- TESTE A/B
- TESTE A/B AMOSTRAGEM
- BOOTCAMP
Python Pandas
Objetivo: Manipular as funções da biblioteca pandas do Pythton, compreendo as suas funcionalidades.
- INSTALAÇÃO E IMPORTAÇÃO DA BIBLIOTECA
- CRIANDO AS PRIMEIRAS ESTRUTURAS
- IMPORTANDO DADOS
- INSERINDO ITEM COM APPEND
- INSPEÇÃO DE CONJUNTO
- INSPEÇÃO DE COLUNA
- INSPEÇÃO DE CONTEÚDO
- BOOTCAMP
- ATRIBUIÇÃO DE DADOS
- FILTROS
- FILTROS UTILIZANDO AND E OR
- DADOS FALTANTES E DUPLICADOS
- BOOTCAMP
- RESUMO ESTATÍSTICO
- AGRUPAMENTO
- VISUALIZAÇÃO DE DADOS
- CONECTANDO DADOS
- SALVANDO DADOS
- BOOTCAMP
Python ETL
Objetivo: Aplicar de forma assertiva a funcionalidade ETL, no formato CSV, banco de dados e API na programação com Python.
- CONHECENDO NOSSO ARQUIVO
- CRIANDO COLUNAS
- CATEGORIZAÇÃO DE DADOS
- TRATANDO VALORES NULOS
- BOOTCAMP
- APAGANDO COLUNAS
- PORQUÊ USAR APIS
- MONTANDO URL
- EXECUTANDO ENVIO APIS
- TRANSFORMANDO DATA
- IDENTIFICANDO COLUNAS
- TRATANDO CONTEÚDOS DATAFRAME
- BOOTCAMP
- EXPORTANDO PARA CSV
- CREDENCIAIS PARA BANCO DE DADOS
- ESCREVENDO EM UM BANCO DE DADOS
- LENDO DADOS EM UM BANCO DE DADOS
- BOOTCAMP
Visualização de Dados
Objetivo: Criar dashboards na ferramenta power bi, conseguindo aplicar técnicas durante todo o ciclo do dado, desde a sua captura dentro da ferramenta até a visualização.
- PASSOS PARA UMA VISUALIZAÇÃO EFICIENTE
- INICIANDO COM POWER BI
- CONECTANDO DADOS
- MÉTRICAS E DIMENSÕES
- GRÁFICO DE BARRA
- FILTROS DE DADOS
- GRÁFICO DE LINHA E SÉRIE TEMPORAL
- GRÁFICO DE PIZZA
- ADICIONANDO CAMPO
- DAX
- CONTROLES DE FILTROS
- GRÁFICO DE DISPERSÃO
- GRÁFICO DE TABELA E TABELA DINÂMICA
- TEXTOS
- RELACIONAMENTO ENTRE DADOS
- GRÁFICO DE MAPA
- OUTROS GRÁFICOS
- DESIGN
- BOOTCAMP
IA e Machine Learning
Objetivo: Compreeder conceitos dos principais modelos e aplicá-los em Python conforme problema estabelecido.
- SUBGRUPOS DA INTELIGÊNCIA ARTIFICIAL
- MACHINE LEARNING
- TIPOS DE APRENDIZAGENS
- FLUXO DE UM PROJETO DE MACHINE LEARNING
- MÉTRICAS DE AVALIAÇÃO
- PRINCIPAIS DESAFIOS
- MODELOS DE CLASSIFICAÇÃO
- NAIVE BAYES
- REGRESSÃO LOGÍSTICA
- K-NN
- HIPEPARÂMETROS
- SVM
- ÁRVORES DE DECISÃO
- RANDON FOREST
- REDES NEURAIS
- MODELOS DE REGRESSÃO
- REGRESSÃO LINEAR
- REGRESSÃO POLINOMIAL
- OUTROS MÉTODOS
- AGRUPAMENTO
- K-MEANS
IA Generativa e Engenharia de Prompts
Objetivo: Compreeder os fundamentos, funcionamento, arquitetura e aplicações práticas de modelos generativos de IA.
- EVOLUÇÃO DA IA GENERATIVA (GPT, BERT, LLAMA, ETC.)
- DIFERENÇAS ENTRE MODELOS DE LINGUAGEM (MLM VS. AR)
- COMO OS TRANSFORMERS FUNCIONAM (ATENÇÃO, EMBEDDINGS, TOKENIZAÇÃO)
- DIFERENÇA ENTRE MODELOS PRÉ-TREINADOS E FINE-TUNED
- TIPOS DE PROMPTS: ZERO-SHOT, FEW-SHOT E CHAIN-OF-THOUGHT
- ESTRUTURAÇÃO DE PROMPTS EFICAZES (CLAREZA, CONTEXTO E INTENÇÃO)
- TESTANDO PROMPTS NO OPENAI PLAYGROUND OU API DO LLAMA
- COMPARAÇÃO DE RESPOSTAS COM DIFERENTES ESTRATÉGIAS DE PROMPTING
- USO DE IA PARA GERAR CÓDIGO SQL E PYTHON (EXEMPLOS PRÁTICOS)
- EXTRAÇÃO DE INSIGHTS AUTOMÁTICOS DE BASES DE DADOS
- COMO MODELOS GENERATIVOS PODEM CRIAR DADOS DE TREINO REALISTAS
- FERRAMENTAS COMO FAKER E GPT PARA GERAÇÃO DE DATASETS
- AUTOMATIZANDO LIMPEZA DE DADOS E DETECÇÃO DE PADRÕES
- USO DE IA PARA GERAÇÃO DE RESUMOS E EXPLICAÇÕES DE DADOS
- CRIANDO UM CHATBOT QUE INTERPRETA CONSULTAS SQL
- APLICANDO IA PARA DOCUMENTAÇÃO AUTOMATIZADA DE CÓDIGO
- O QUE É RAG E COMO ELE MELHORA A PRECISÃO DOS MODELOS
- COMPARAÇÃO ENTRE FINE-TUNING VS. RAG
- INTEGRAÇÃO DE RAG COM SQL (EXEMPLO DE BUSCA EM BANCOS DE DADOS)
- HANDS-ON FINAL: CONSTRUINDO UM PIPELINE COM IA GENERATIVA + RAG
Imersão de carreira Harve
Objetivo: Neste módulo, você vai vivenciar o dia a dia de um cientista de dados através de projetos reais. Uma oportunidade de unir todo o conhecimento e práticas feitas durante a formação para uma verdadeira imersão no mercado de trabalho digital.
Práticas reais que você vai desenvolver durante a formação
Práticas reais que você vai desenvolver durante a formação

Análise de Dados dos sobreviventes do Titanic
Você vai poder analisar os dados de um dos desastres mais impressionantes da história.

Análise de Dados pessoais da Netflix
Com a linguagem Python, vamos extrair e interpretar dados de comportamento de utilização da plataforma.

Trabalhando com dados da prefeitura
Com o banco de dados da prefeitura, analise e trate dados para identificar tendências e peculiaridades entre bairros.

Analisando jogadores da FIFA
Use dados reais da FIFA para analisar mais de 16 mil jogadores.

Desvendando as vendas de uma grande varejista
Quantas vendas, ticket médio, melhores meses e muitas outras explorações de dados.

Criações e análises de gráficos
Crie visualizações intuitivas que geram insights para tomadas de decisões
baseadas em dados.

Projeto I.A Machine Learning
Vamos criar e aplicar modelos de inteligência artificial e aprendizagem de máquina.
Chegou a hora. Vamos juntos?
Formação Prática Completa em Cientista de Dados
Presencial em Curitiba – Harve
Início das aulas: -
Término das aulas: -Dias de aula: - (19h às 22h30)
Formas de pagamento: pix, transferência ou em até 12x s/juros
Metodologia prática validada
Mentorias individuais
Turmas reduzidas
Alto índice de satisfação
Facilitadores
Aprenda na prática os caminhos para ser um cientista de dados com os profissionais mais renomados do Brasil no curso data science curitiba Harve

Logistics Intelligence and Efficiency Specialist no Grupo Boticário. Engenheiro de produção e pós-graduado em Data Science com 7 anos de experiência em Bussiness Intelligence, Logística e Transformação Digital. Habilidades incluem capacidade analítica de dados, gestão de projetos, comunicação efetiva, criatividade e oratória. Especializado em processos ETL, Power BI, SQL, DAX e M.










Cientista de Dados Sênior na St-One. Com mais de 5 anos de experiência, desenvolveu as principais habilidades como Programação em Python, Inteligência Artificial e Desenvolvimento de Projetos. Atuou em projetos como no desenvolvimento de produto voltado para eficiência energética com uso de inteligência artificial pela UTFPR.

Engenheiro de Dados no Grupo Boticário. Possui mais de 7 anos de experiência com Python e 3 com engenharia de dados. Especialista em manutenção e desenvolvimento de pipelines de ingestão de dados utilizando ferramentas GCP (BigQuery, CloudFunction, DataFusion, etc..) orquestradas por Airflow. Linguagens principais: SQL e Python.


Head of Technology na Condo Consult. Formado em Economia | BI | Python | Pandas. Liderança de projetos estratégicos de tecnologia e estruturação de dados; Desenvolvimento e manutenção de pipelines de ETL para integração e consolidação de dados; Criação e evolução de soluções em Business Intelligence para suporte à tomada de decisão; Desenvolvimento de aplicações web customizadas para automação de processos internos.
Nossos facilitadores já geraram resultados para:
Nossos facilitadores já geraram resultados para:






A Metodologia Harve

Nós amamos o ensino presencial
Travou no exercício? O facilitador Harve está do lado para ajudar.
Turmas reduzidas de no máximo 20 alunos. Mais atenção do facilitador.
Mentorias individuais. Só você e o facilitador tirando dúvidas específicas.
Aceleração e avaliação de aprendizagem
Nossa metodologia acelera o aprendizado nas fases iniciais com foco na aplicação para avançar rapidamente até os níveis mais avançados. Ao final de cada módulo, realizamos uma avaliação de aprendizagem para entender como está a evolução do aluno e também mapear pontos de avanço de forma individual.

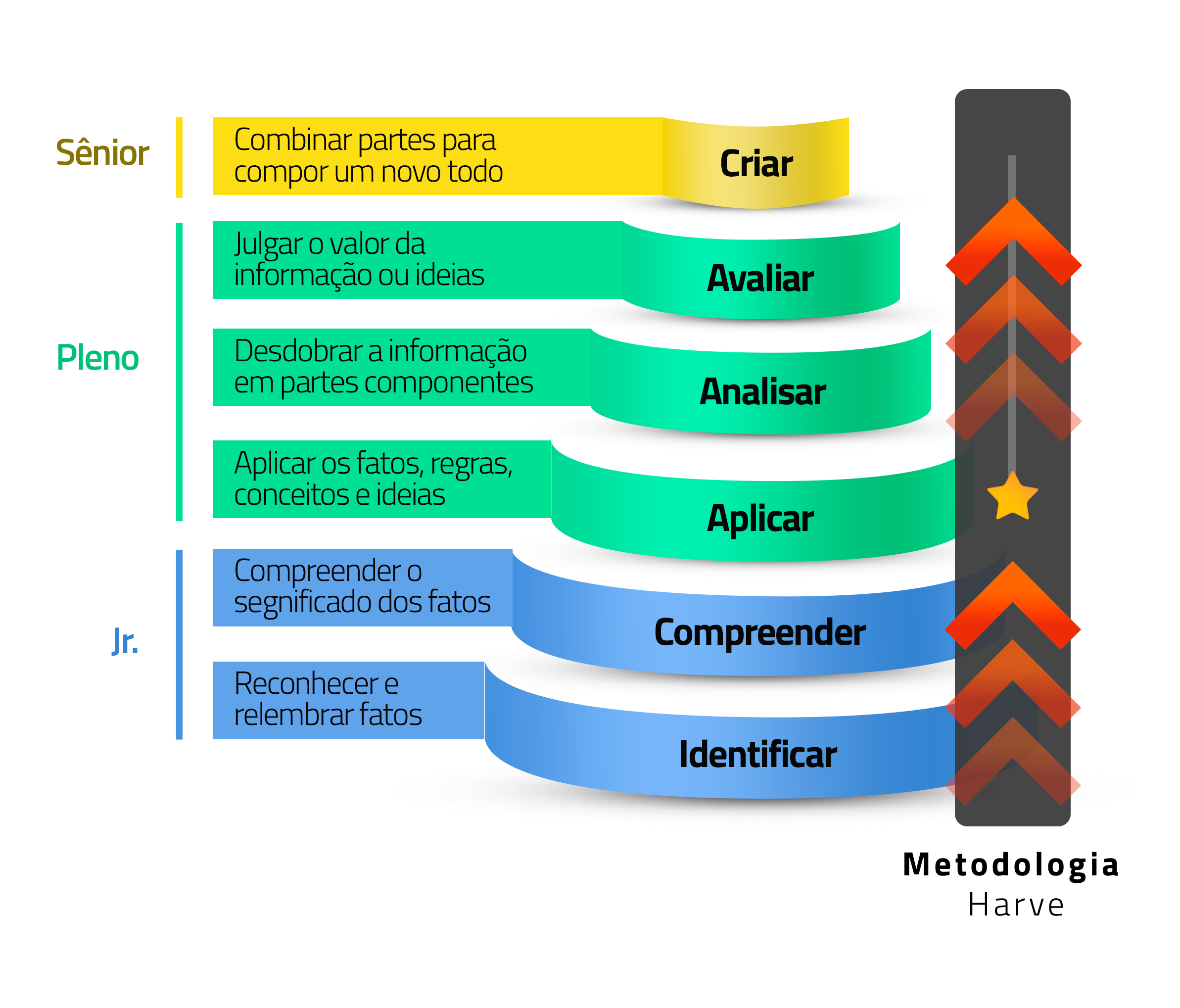

Práticas contínuas e materiais de estudo
Garantimos que para cada tema de estudo teórico, logo em seguida venham as fases de prática como a descoberta guiada e o hands on. A junção da prática contínua nas fases iniciais adiciona mais aceleração no aprendizado.
Nossa metodologia garante:
60% Prática
40% Teoria
O seu portal para as carreiras digitais
Veja alguns dos nossos alunos que já atravessaram o portal para uma nova perspectiva de vida:
 Marília Nakayama
Marília Nakayama
Aluna Harve Cientista de Dados
Contratada:
Grupo Boticário
 Matehus Lana
Matehus Lana
Aluno Harve Cientista de Dados
Contratado:
Dell Technologies
 Carolina Dias
Carolina Dias
Aluna Harve Cientista de Dados
Contratada:
INTERMETALINK
 André Luis Krasinski
André Luis Krasinski
Aluno Harve Cientista de Dados
Contratado:
ST-One
66%
Índice de empregabilidade de alunos Harve
nos 6 primeiros meses após a formação
66%
Índice de empregabilidade de alunos Harve
nos 6 primeiros meses após a formação
300
+ de 300 turmas formadas
2500
+ de 2500 alunos impactados
12000
+ de 12000 horas de conteúdos ministrados





São 112 horas de conteúdo completo para você iniciar sua carreira em data science
Venha aprender em 4 meses com conteúdo atualizado e mentores renomados do mercado no Curso Data Science Curitiba Harve.